多次元配列
これまでに登場した配列は、メモリ上に、要素が連続的に並んだものでした。これは図にすると、次のようになります(数字は添字です)。
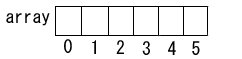
ここで、各要素がそれぞれ配列だったらどうなるでしょうか? 図で書くと、次のようになると考えられます。
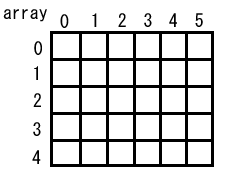
横方向に要素が並んでいましたが、それぞれの要素から縦方向にも配列が伸びたという状態です。結果、表のような形になるとイメージできます。このような配列は、二次元配列 (two-dimensional array) と呼ばれます。これに対して、最初の配列は、一次元配列 (one-dimensional array) です。二次元以上になった配列を、多次元配列 (multi-dimensional array) と呼びます。
正確にいえば、C言語の多次元配列は、配列の配列 (array of array) と呼ぶほうが適切ですが、多次元配列と呼ばれることが多いので、今後も多次元配列と表現します。
二次元 “以上” と書いたように、三次元以上にすることが可能です。たとえば、三次元配列であれば、次のようなイメージになるでしょう。
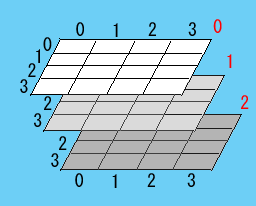
これもやはり、4次元、5次元・・・と増やすことが可能ですが、ほとんどの人は4次元以上をイメージすることができないはずです(現実世界が3次元ですから)。実際、まともなイメージ図は描けませんし、4次元以上の配列は避けるのが無難です。
多次元配列は、次のように宣言します。
int array[5][6]; // 二次元配列
int array[3][4][4]; // 三次元配列次元が増えるたびに、要素を特定するための添字の個数も増えていきます。初期値を与える場合は、分かりやすさのために、次元ごとに { } で囲むように書きます。
int array[5][6] = {
{0, 1, 2, 3, 4, 5},
{0, 1, 2, 3, 4, 5},
{0, 1, 2, 3, 4, 5},
{0, 1, 2, 3, 4, 5},
{0, 1, 2, 3, 4, 5}
};
int array[3][4][4] = {
{
{0, 1, 2, 3},
{0, 1, 2, 3},
{0, 1, 2, 3},
{0, 1, 2, 3}
},
{
{0, 1, 2, 3},
{0, 1, 2, 3},
{0, 1, 2, 3},
{0, 1, 2, 3}
},
{
{0, 1, 2, 3},
{0, 1, 2, 3},
{0, 1, 2, 3},
{0, 1, 2, 3}
}
};実際には、{ } は1組だけあれば認識されますが、分かりづらくなるかもしれません。
int array[5][6] = {
0, 1, 2, 3, 4, 5,
0, 1, 2, 3, 4, 5,
0, 1, 2, 3, 4, 5,
0, 1, 2, 3, 4, 5,
0, 1, 2, 3, 4, 5
};
int array[3][4][4] = {
0, 1, 2, 3,
0, 1, 2, 3,
0, 1, 2, 3,
0, 1, 2, 3,
0, 1, 2, 3,
0, 1, 2, 3,
0, 1, 2, 3,
0, 1, 2, 3,
0, 1, 2, 3,
0, 1, 2, 3,
0, 1, 2, 3,
0, 1, 2, 3
};また、要素数の指定を省略して、コンパイラに要素数を判断させることができるのは、一番左側の [] だけです。
int array[][6] = {
{0, 1, 2, 3, 4, 5},
{0, 1, 2, 3, 4, 5},
{0, 1, 2, 3, 4, 5},
{0, 1, 2, 3, 4, 5},
{0, 1, 2, 3, 4, 5}
};
int array[][4][4] = {
{
{0, 1, 2, 3},
{0, 1, 2, 3},
{0, 1, 2, 3},
{0, 1, 2, 3}
},
{
{0, 1, 2, 3},
{0, 1, 2, 3},
{0, 1, 2, 3},
{0, 1, 2, 3}
},
{
{0, 1, 2, 3},
{0, 1, 2, 3},
{0, 1, 2, 3},
{0, 1, 2, 3}
}
};多次元配列になっても、メモリ上で、要素が連続的に並ぶ性質は変わりません。
#include <stdio.h>
int array[5][6] = {
{0, 1, 2, 3, 4, 5},
{0, 1, 2, 3, 4, 5},
{0, 1, 2, 3, 4, 5},
{0, 1, 2, 3, 4, 5},
{0, 1, 2, 3, 4, 5}
};
int main(void)
{
for (int i = 0; i < 5; ++i) {
for (int j = 0; j < 6; ++j) {
printf("%p ", &array[i][j]);
}
printf("\n");
}
}実行結果:
00F68000 00F68004 00F68008 00F6800C 00F68010 00F68014
00F68018 00F6801C 00F68020 00F68024 00F68028 00F6802C
00F68030 00F68034 00F68038 00F6803C 00F68040 00F68044
00F68048 00F6804C 00F68050 00F68054 00F68058 00F6805C
00F68060 00F68064 00F68068 00F6806C 00F68070 00F68074要素を順番にアクセスする必要がある場合には、できるだけ、メモリアドレスも連続するような順番で行う方が、処理効率が高まる可能性があります。ですから、二次元配列の全要素を順番にアクセスするときには、以下のように書くのではなく、
for (int i = 0; i < 6; ++i) {
for (int j = 0; j < 5; ++j) {
array[j][i] = i * j;
}
}以下のように書いた方が良いといえます。
for (int i = 0; i < 5; ++i) {
for (int j = 0; j < 6; ++j) {
array[i][j] = i * j;
}
}つまり、array[i][j][k] のように添字を指定する場合なら、後ろにある添字の方が速くカウントが進んでいき、手前側にある添字のカウントの方が遅れて進む方が良いということです。
二次元配列を関数に渡すことを考えてみます。
式の中であらわれた配列は、暗黙的にポインタに変換されるのでした。二次元配列ならどうなるでしょうか? たとえば、int[][] であれば、int** でなりそうに思えますが、そうはなりません。
暗黙的に変換できるのは、「配列」から「ポインタ」だけです。「配列の配列」から一気に「ポインタへのポインタ」に変換されることはないのです。したがって、int[][] は int[] を指すポインタに変換されます。
これはかなり分かりづらいので、二次元配列のイメージ図で考えてみます。
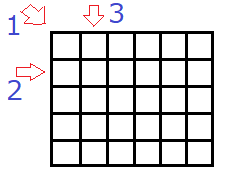
図中の矢印は、「配列」を指し示すポインタを考えたときに、あり得そうな3種類の方法を表しています。つまり、以下の3通りです。
- 二次元配列全体を指すような矢印をイメージする
- 横方向(行方向)に、どこか1行を指す矢印をイメージする
- 縦方向(列方向)に、どこか1列を指す矢印をイメージする
配列の配列を、(一次元)配列を指すポインタに変換したときのイメージとして正しいのは2番です。
1番は、二次元配列全体を指しているので、int[] を指すポインタのイメージには合いません。3番は、要素のメモリアドレスが連続的に並ばないので、これでは配列ではなくなってしまいます。
さて、問題なのは、2番のイメージに沿ったポインタは、どんな型で表現されるのかという点です。「int[]*」でしょうか? それとも「int*[]」でしょうか? どちらでもなく、このイメージ図の場合ならば、「int (*)[6]」が正解です。
この謎めいた表現を理解する考え方はいろいろありますが、たとえばこう考えてみましょう。
先ほどの図で、2番の矢印は、二次元配列のどこか1つの行を、一次元配列とみなして、その配列を指しているのです。ここで、ポインタに対するインクリメントの挙動を考えてみます。
int型のポインタに対して ++演算子を適用すると、int1個分の大きさ(sizeof(int)) だけ先へ移動するのでした(第32章)。同じように考えると、1行分の配列を指しているポインタをインクリメントしたら、次の行へ移ると考えられます。つまり、「sizeof(int) * 1行に含まれている要素数」だけ加算される訳です。
この計算を実現するには、「1行に含まれている要素数」という情報をきちんと持っていないといけません。「int**」のような型になってしまったら、要素数が分かりません。「int (*)[6]」という型で、[6] の部分が、「1行に含まれている要素数(言い換えると列の個数)」です。
要するに、「int (*)[6]」は、「int型の要素を 6個持った一次元配列を指すポインタ型」と解釈すればよいということです。
ここまでを踏まえて、実際のプログラムを見てみましょう。
#include <stdio.h>
#define ARRAY_COL_NUM 6 // 配列の列の数
#define ARRAY_ROW_NUM 5 // 配列の行の数
void print_array(const int (*array)[ARRAY_COL_NUM], int row, int col);
int main(void)
{
int array[ARRAY_ROW_NUM][ARRAY_COL_NUM];
// 全要素へ値を格納
for (int i = 0 ; i < ARRAY_ROW_NUM; ++i) {
for (int j = 0 ; j < ARRAY_COL_NUM; ++j) {
array[i][j] = i * 10 + j;
}
}
// 要素を出力
print_array(array, ARRAY_ROW_NUM, ARRAY_COL_NUM);
}
/*
二次元配列の要素を出力。
引数:
array: 二次元配列の先頭メモリアドレス。
row: 列の数。
col: 行の数。
*/
void print_array(const int (*array)[ARRAY_COL_NUM], int row, int col)
{
for (int i = 0 ; i < row; ++i) {
for (int j = 0; j < col; ++j) {
printf("%02d ", array[i][j]);
}
printf("\n");
}
}実行結果:
00 01 02 03 04 05
10 11 12 13 14 15
20 21 22 23 24 25
30 31 32 33 34 35
40 41 42 43 44 45print_array関数の仮引数に注目してください。「const int (*array)[ARRAY_COL_NUM]」という複雑な表現になっていますが、ARRAY_COL_NUM は、二次元配列の列の個数ですから、先ほどの説明どおりです。const は、関数内で書き換えないことを示すためのものです。
なお、( ) が必要であることに注意してください。( ) がないと、意味が変わります。
int (*array)[6]; // int型で要素数6 の配列 へのポインタ
int* array[6]; // int型へのポインタ の配列で要素数は 6