チェイン法 🔗
チェイン法(分離連鎖法)は、同じハッシュ値になるデータを、連結リスト📘(データ構造編第3章)によってつなげていくことによって、衝突を解決する方法です。イメージとしては、次の図のようになります。
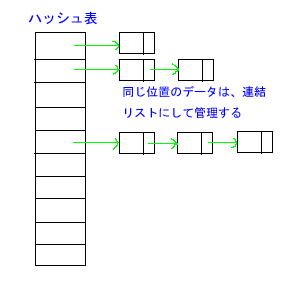
こうすれば、データを格納する際、決定された格納位置にすでにほかのデータがあれば、連結リストに要素を追加することで対応できます。
それでは、チェイン法によるハッシュ探索のプログラムを取り上げます。ハッシュ探索に関わる部分は hash.c と hash.h に分離しています。また、チェイン法の実装のために連結リストを必要としますが、これはコードライブラリにあるサンプル実装 ppps_int_slistを使っています。
// main.c
#include <stdio.h>
#include <string.h>
#include "hash.h"
static void create_hash(void);
static void delete_hash(void);
static void print_explain(void);
static void print_blank_lines(void);
static enum CmdRetValue_tag get_cmd(void);
static enum CmdRetValue_tag cmd_add(void);
static enum CmdRetValue_tag cmd_remove(void);
static enum CmdRetValue_tag cmd_search(void);
static enum CmdRetValue_tag cmd_exit(void);
static void add_elem(int value);
static void remove_elem(int value);
static int search_elem(int value);
static void get_line(char* buf, size_t size);
// コマンド
enum Cmd_tag {
CMD_ADD,
CMD_REMOVE,
CMD_SEARCH,
CMD_EXIT,
CMD_NUM
};
// コマンド文字列の種類
enum CmdStr_tag {
CMD_STR_SHORT,
CMD_STR_LONG,
CMD_STR_NUM
};
// コマンドの戻り値
enum CmdRetValue_tag {
CMD_RET_VALUE_CONTINUE,
CMD_RET_VALUE_EXIT,
};
// コマンド文字列
static const char* const CMD_STR[CMD_NUM][CMD_STR_NUM] = {
{ "a", "add" },
{ "r", "remove" },
{ "s", "search" },
{ "e", "exit" }
};
// コマンド実行関数
typedef enum CmdRetValue_tag (*cmd_func)(void);
static const cmd_func CMD_FUNC[CMD_NUM] = {
cmd_add,
cmd_remove,
cmd_search,
cmd_exit
};
static Hash gHash;
int main(void)
{
create_hash();
while( 1 ){
print_explain();
if( get_cmd() == CMD_RET_VALUE_EXIT ){
break;
}
print_blank_lines();
}
delete_hash();
return 0;
}
/*
ハッシュ表を作成
*/
void create_hash(void)
{
gHash = hash_create( 100 );
}
/*
ハッシュ表を削除
*/
void delete_hash(void)
{
hash_delete( gHash );
gHash = NULL;
}
/*
説明文を出力
*/
void print_explain(void)
{
puts( "コマンドを入力してください。" );
printf( " データを登録: %s (%s)\n", CMD_STR[CMD_ADD][CMD_STR_SHORT], CMD_STR[CMD_ADD][CMD_STR_LONG] );
printf( " データを削除: %s (%s)\n", CMD_STR[CMD_REMOVE][CMD_STR_SHORT], CMD_STR[CMD_REMOVE][CMD_STR_LONG] );
printf( " データを探索: %s (%s)\n", CMD_STR[CMD_SEARCH][CMD_STR_SHORT], CMD_STR[CMD_SEARCH][CMD_STR_LONG] );
printf( " 終了する: %s(%s)\n", CMD_STR[CMD_EXIT][CMD_STR_SHORT], CMD_STR[CMD_EXIT][CMD_STR_LONG] );
puts( "" );
}
/*
空白行を出力
*/
void print_blank_lines(void)
{
puts( "" );
puts( "" );
}
/*
コマンドを受け付ける
戻り値:
終了コマンドを入力されたら 0 を返す。
それ以外のときは 0以外の値を返す。
*/
enum CmdRetValue_tag get_cmd(void)
{
char buf[20];
get_line( buf, sizeof(buf) );
enum Cmd_tag cmd = CMD_NUM;
for( int i = 0; i < CMD_NUM; ++i ){
if( strcmp( buf, CMD_STR[i][CMD_STR_SHORT] ) == 0
|| strcmp( buf, CMD_STR[i][CMD_STR_LONG] ) == 0
){
cmd = i;
break;
}
}
if( 0 <= cmd && cmd < CMD_NUM ){
return CMD_FUNC[cmd]();
}
else{
puts( "そのコマンドは存在しません。" );
}
return CMD_RET_VALUE_CONTINUE;
}
/*
addコマンドの実行
*/
enum CmdRetValue_tag cmd_add(void)
{
char buf[40];
int value;
puts( "追加する数値データを入力してください。" );
fgets( buf, sizeof(buf), stdin );
sscanf( buf, "%d", &value );
add_elem( value );
return CMD_RET_VALUE_CONTINUE;
}
/*
removeコマンドの実行
*/
enum CmdRetValue_tag cmd_remove(void)
{
char buf[40];
int value;
puts( "削除する数値データを入力してください。" );
fgets( buf, sizeof(buf), stdin );
sscanf( buf, "%d", &value );
remove_elem( value );
return CMD_RET_VALUE_CONTINUE;
}
/*
searchコマンドの実行
*/
enum CmdRetValue_tag cmd_search(void)
{
char buf[40];
int value;
puts( "探索する数値データを入力してください。" );
fgets( buf, sizeof(buf), stdin );
sscanf( buf, "%d", &value );
if( search_elem( value ) ){
puts( "見つかりました。" );
}
else{
puts( "見つかりませんでした。" );
}
return CMD_RET_VALUE_CONTINUE;
}
/*
exitコマンドの実行
*/
enum CmdRetValue_tag cmd_exit(void)
{
puts( "終了します。" );
return CMD_RET_VALUE_EXIT;
}
/*
要素を追加する
引数:
value: 追加する要素の数値データ。
*/
void add_elem(int value)
{
hash_add( gHash, value );
}
/*
要素を削除する
引数:
value: 削除する要素の数値データ。
*/
void remove_elem(int value)
{
hash_remove( gHash, value );
}
/*
要素を探索する
引数:
value: 探索する要素の数値データ。
戻り値:
発見できたら 0以外、発見できなければ 0 を返す。
*/
int search_elem(int value)
{
return hash_search( gHash, value ) != NULL;
}
/*
標準入力から1行分受け取る
受け取った文字列の末尾には '\0' が付加される。
そのため、実際に受け取れる最大文字数は size - 1 文字。
引数:
buf: 受け取りバッファ
size: buf の要素数
戻り値:
buf が返される
*/
void get_line(char* buf, size_t size)
{
fgets(buf, size, stdin);
// 末尾に改行文字があれば削除する
char* p = strchr(buf, '\n');
if (p != NULL) {
*p = '\0';
}
}// hash.c
#include "hash.h"
#include "ppps_int_slist.h"
#include <stdio.h>
#include <stdlib.h>
struct Hash_tag {
PPPSIntSlist* table; // ハッシュ表
size_t size; // data の要素数
};
static size_t hash_func(Hash hash, int key);
static void* xmalloc(size_t size);
/*
ハッシュ表を作る
*/
Hash hash_create(size_t size)
{
struct Hash_tag* hash = xmalloc( sizeof(struct Hash_tag) );
hash->table = xmalloc( sizeof(PPPSIntSlist) * size );
for( size_t i = 0; i < size; ++i ){
hash->table[i] = ppps_int_slist_create();
}
hash->size = size;
return hash;
}
/*
ハッシュ表を削除する
*/
void hash_delete(Hash hash)
{
for( size_t i = 0; i < hash->size; ++i ){
ppps_int_slist_delete( hash->table[i] );
}
free( hash->table );
free( hash );
}
/*
ハッシュ表にデータを追加する
*/
void hash_add(Hash hash, int data)
{
size_t index = hash_func( hash, data );
ppps_int_slist_add_front( hash->table[index], data );
}
/*
ハッシュ表からデータを削除する
*/
void hash_remove(Hash hash, int data)
{
size_t index = hash_func( hash, data );
ppps_int_slist_delete_elem( hash->table[index], data );
}
/*
ハッシュ表からデータを探索する
*/
int* hash_search(Hash hash, int data)
{
size_t index = hash_func( hash, data );
PPPSIntSlist elem = ppps_int_slist_search( hash->table[index], data );
if( elem == NULL ){
return NULL;
}
return &elem->value;
}
/*
ハッシュ関数
*/
size_t hash_func(Hash hash, int key)
{
return key % hash->size;
}
/*
エラーチェック付きの malloc関数
*/
void* xmalloc(size_t size)
{
void* p = malloc( size );
if( p == NULL ){
fputs( "メモリ割り当てに失敗しました。", stderr );
exit( EXIT_FAILURE );
}
return p;
}// hash.h
#ifndef HASH_H_INCLUDED
#define HASH_H_INCLUDED
typedef struct Hash_tag* Hash;
/*
ハッシュ表を作る
引数:
size: ハッシュ表の大きさ
戻り値:
作成されたハッシュ表。
使い終わったら、hash_delete関数に渡して削除する。
*/
Hash hash_create(size_t size);
/*
ハッシュ表を削除する
引数:
hash: hash_create関数で作成したハッシュ表
*/
void hash_delete(Hash hash);
/*
ハッシュ表にデータを追加する
引数:
hash: hash_create関数で作成したハッシュ表
data: 追加するデータ
*/
void hash_add(Hash hash, int data);
/*
ハッシュ表からデータを削除する
引数:
hash: hash_create関数で作成したハッシュ表
data: 削除するデータ
*/
void hash_remove(Hash hash, int data);
/*
ハッシュ表からデータを探索する
引数:
hash: hash_create関数で作成したハッシュ表
data: 探索するデータ
戻り値:
ハッシュ表の要素へのポインタ。
見つからなければ NULL。
*/
int* hash_search(Hash hash, int data);
#endifこのプログラムを実行すると、コマンドの入力を求められます。たとえば、“a” または “add” と入力すれば、ハッシュ表へ要素を追加しようとします。このコマンドの場合は、続けて、追加する要素の入力を求められます。
ハッシュ表への要素の追加、要素の削除、探索のコマンドを実装しています。とりあえず、適当に追加や削除を行い、動作を確かめてみてください。
それでは、実装内容を確認していきましょう。
ハッシュ表の作成 🔗
ハッシュ表を探索する関数は、hash_create関数です。
ハッシュ表の各バケットが連結リストになります。初期状態では、連結リストの先頭部分だけが並んだような状態になっています。
引数にはハッシュ表の要素数を指定しますが、実際にはバケットは1つ1つが連結リストになるのですから、ここで指定した要素数を越えて要素を追加できます。だからといって、要素数を極端に小さく指定すると、衝突が頻発することになります。
チェイン法において衝突が起こるということは、連結リストが伸びていくということです。その結果、連結リストの要素の動的な割り当てが行われることによる速度低下や、メモリ使用量の増加につながるほか、探索の際にも、連結リスト内をたどる回数が増えるため、全体的に性能が悪化します。
ですから、ハッシュ表の要素数を適切に決める必要性があります。とはいえ、これは非常に難しく、色々試してみるしかありません。また、素数を使うとよく、2 のべき乗を使うのは悪いことが知られています。
なお、ハッシュ表の要素数が、実際に格納する可能性がある要素数よりも大きく取ったからといって、衝突が起こらないことを保証できるわけではないことに注意してください。ハッシュ関数が生成するハッシュ値が同じになり得るのなら、やはり衝突は起こります。ハッシュ表に十分な要素数があるのと同時に、ハッシュ値も被らないことが保証されないかぎり、衝突は避けられません。
ハッシュ表への要素の追加 🔗
要素の追加は、hash_add関数で行っています。
まず、hash_func関数を呼び出して、格納位置を決定しています。hash_func関数は名前のとおり、ハッシュ関数を実装したものです。このサンプルプログラムでは、ハッシュ関数は、渡された整数値をハッシュ表の要素数で割った余りを返しています。
格納位置が決定したら、その位置にある連結リストの先頭に挿入しています。連結リスト上の要素の並び順に特に意味がないのであれば、先頭に挿入した方が高速です。
ハッシュ表からの要素の削除 🔗
要素の削除は、hash_remove関数で行っています。
ここでもやはり、hash_func関数を呼び出して格納位置を調べます。その位置にある連結リストをたどることで、目的の要素を見つけ出せるので、あとは連結リストからの削除処理を行えば実現できます。
ハッシュ表からの要素の探索 🔗
要素の探索は、hash_search関数で行っています。
探索は、削除とほとんど同じです。ハッシュ関数によって格納位置を調べ、そこにある連結リストをたどっていきます。