木構造 🔗 この章では、木構造(ツリー) 📘 📘 第3章 )と同様に、非常に重要なデータ構造です。
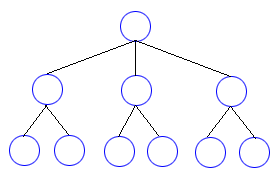
まず、木構造の概念図を見てください。
木構造
この概念図において、○ の部分を節 📘 枝 と呼びます。この概念図で、上下を逆さまにしてみれば、木のような形をしていることが分かると思います。これが木構造と呼ばれる理由です。
ここで、ある節から見て、その1つ下にある節のことを子 と呼び、逆に1つ上の節を親 と呼びます。
この辺りの用語は、家系図を見るように考えればいいです。兄弟、従弟、先祖、子孫などの用語もあります。ちなみに「兄弟」は brother ではなく sibling の方です。
一番上にある節のことを根(ルート) と呼び、一番下にある節のことを葉 と呼びます。根は、つねに1つしかありませんが、葉は複数あるかもしれません。なお、葉のことを外部節(外部ノード) 、葉以外の節を内部節(内部ノード) と呼ぶことがあります。
また、木には高さ(深さ) という概念があります。これは、根から一番遠い葉までに通過する枝の個数によって表現されます。
1つの節が、2つ以下の子を持つような木構造を二分木 📘
1つの節が3つ以上の子を持つ木構造も考えられます。このような木構造は多分木 と呼ばれます。
1つの節が1つしか子を持たない場合もありえます。これはもはや木のような形にはなりませんが、これでも木構造とみなすことはできます。このような形の木構造は、もはや連結リストと同じかたちをしています。
木構造の利点は、格納されているデータを見つける効率の良さにあるのですが、連結リストと同じかたちになってしまった木構造ではその利点が消えてしまいます。もはや連結リストと同じものなのですから、先頭から要素を1つ1つ辿っていくしかなくなるためです。
木構造に要素を追加していくときに、節を置く位置を誤ると、このような状態になってしまうことがあります。木構造の性能上の利点をきちんと得るには、この問題への対策を考える必要があります。
木構造が連結リストのような形になってしまう問題については、次の第8章 で取り上げることにして、本章ではきちんと二分木になっている前提の話をします。
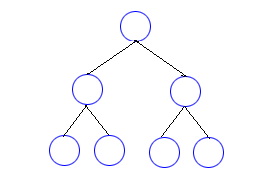
二分木 🔗 二分木とは、葉以外のすべての節が、2つ以下の子を持つような木構造のことです。 もし、必ず2つの子を持つようならば、全二分木 📘 完全二分木 📘
概念図は次のようになります。
二分木
この概念図は、葉以外のすべての節が子を必ず2つずつ持っており、どの葉も同じ深さにあるので、完全二分木になっていると言えます。
C言語のプログラムでは、二分木を次のように表現できます。
struct Node_tag { int value; // この節のデータ struct Node_tag* left; // 左の子へのポインタ struct Node_tag* right; // 右の子へのポインタ }; この構造体は1つの節を表します。通常、節ごとに動的にメモリ割り当てを行い、その都度、left と right を適切に設定、あるいは更新します(連結リストと同じ感覚で考えればいいです)。
子がない場合は、left や right には、NULL を入れておけばよいでしょう。
value というメンバは、この節に置かれた具体的なデータを表すもので、もちろん int型である必要はなく、任意のデータを任意の数だけ置けます。
この構造体をよく観察すると、双方向連結リスト(第4章 )の構造体とまったく同じ形をしていることが分かります。違いは、next と prev という名前のポインタが、left と right に変わっただけです。構造体の形は一緒でも、それをどう扱うかによって、実現できることはまったく異なります。
この構造体を見ると分かるように、親に向かうポインタを持っていません。もちろん、ポインタを1つ付け加えれば、親をたどれますが、その必要性がないのなら不要です。木構造は、根からその子をたどることを繰り返して、目的の節へ行き着くというように利用することが多く、親をたどる必要性がない場合もよくあります。
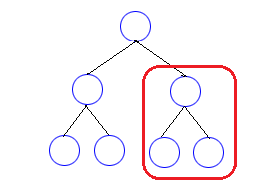
再帰的な性質 🔗 次の図は、二分木の概念図に、赤い枠を加えたものです。
二分木
二分木の一部分を囲っていますが、この囲まれた部分だけを観察してみると、その部分もやはり二分木になっていることが分かります。
このように、木構造はその一部分だけを取り出してみても、やはり木構造の形をしているという特徴があります。ここで、一部分の木のことを部分木 と呼びます。
この概念図の場合、全体としての根の右側にある部分木を囲っていますが、この場合、根に対して右部分木 と呼びます。左側にあれば左部分木 と呼ばれます。
もっと大きな木構造であれば、部分木の中にさらに部分木が、その中にさらに部分木があるという構造になります。このように、自分自身の一部が、自分自身と同じ形状をしているような構造は、再帰的な構造 と呼ばれます。
データ構造が再帰的になっているのであれば、プログラムでも再帰処理を活用しやすくなります。次の項 で、すべての節を調べつくす処理を取り上げますが、ここでは再帰処理を利用しています。
走査 🔗 二分木に含まれるすべての節を調べたいとします。このような処理を、走査(トラバース) と呼びます。ここで重要な点は、「すべてをもらさず」「同じものを重複せず」 に調べつくすことです。
二分木に対する走査の方法には、大きく分けると、深さ優先探索 と幅優先探索 の2つがあります。前者はさらに、行きがけ順探索 、通りがけ順探索 、帰りがけ順探索 に分類できます。これらは、調べる節の順序が異なります。
深さ優先探索では、根から始めて、葉に行き着くまで子をたどっていきます 。葉まで行き着いたら、その親に戻り、先ほど辿った側ではないもう一方の子を調べに行き、やはり葉までたどります。これを繰り返せば、いずれすべての節を調べられます。
行きがけ順探索、通りがけ順探索、帰りがけ順探索の違いは、根とその2つの子をどんな順序で調べるかです。
行きがけ順探索では、根→左の部分木→右の部分木の順で調べます
通りがけ順探索では、左の部分木→根→右の部分木の順で調べます
帰りがけ順探索では、左の部分木→右の部分木→根の順で調べます
もう1つの方法である幅優先探索は、まず根を調べ、次に1つ深い階層の左部分木、右部分木を調べます。1つの階層の節をすべて網羅してから、次の階層へ降りることを繰り返します 。
それでは実際に、それぞれの走査を実装してみましょう。
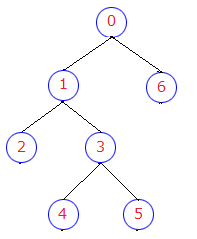
#include <stdio.h> #include <string.h> #include <stdlib.h> #define SIZE_OF_ARRAY ( array ) ( sizeof ( array )/ sizeof ( array [ 0 ])) // コマンド enum Cmd_tag { , , , , }; // コマンド文字列の種類 enum CmdStr_tag { , , }; // コマンドの戻り値 enum CmdRetValue_tag { , , }; // コマンド文字列 static const char * const CMD_STR[ CMD_NUM][ CMD_STR_NUM] = { { "r" , "pre" }, { "i" , "in" }, { "p" , "post" }, { "e" , "exit" } }; // 二分木 struct Node_tag { int value; struct Node_tag* left; struct Node_tag* right; }; typedef struct Node_tag* BinaryTree; static BinaryTree create_binary_tree( void ); static void delete_binary_tree( BinaryTree tree); static void print_explain( void ); static void print_blank_lines( void ); static enum CmdRetValue_tag get_cmd( void ); static enum CmdRetValue_tag cmd_pre_order( void ); static enum CmdRetValue_tag cmd_in_order( void ); static enum CmdRetValue_tag cmd_post_order( void ); static enum CmdRetValue_tag cmd_exit( void ); static void pre_order( BinaryTree tree); static void in_order( BinaryTree tree); static void post_order( BinaryTree tree); static void get_line( char * buf, size_t size); // コマンド実行関数 typedef enum CmdRetValue_tag (* cmd_func)( void ); static const cmd_func CMD_FUNC[ CMD_NUM] = { , , , }; static BinaryTree gTree; int main( void ) { = create_binary_tree(); while ( 1 ){ (); if ( get_cmd() == CMD_RET_VALUE_EXIT ){ break ; } (); } ( gTree ); return 0 ; } /* 二分木を作成 ここでは、 0 / \ 1 6 / \ 2 3 / \ 4 5 という形の二分木を作っている。 */ ( void ) { [ 7 ]; for ( size_t i = 0 ; i < SIZE_OF_ARRAY( node); ++ i ){ [ i] = malloc( sizeof ( struct Node_tag) ); [ i]-> value = ( int ) i; } [ 0 ]-> left = node[ 1 ]; [ 0 ]-> right = node[ 6 ]; [ 1 ]-> left = node[ 2 ]; [ 1 ]-> right = node[ 3 ]; [ 2 ]-> left = NULL; [ 2 ]-> right = NULL; [ 3 ]-> left = node[ 4 ]; [ 3 ]-> right = node[ 5 ]; [ 4 ]-> left = NULL; [ 4 ]-> right = NULL; [ 5 ]-> left = NULL; [ 5 ]-> right = NULL; [ 6 ]-> left = NULL; [ 6 ]-> right = NULL; return node[ 0 ]; } /* 二分木を削除 */ void delete_binary_tree( BinaryTree tree) { if ( tree == NULL ){ return ; } ( tree-> left ); ( tree-> right ); ( tree ); } /* 説明文を出力 */ void print_explain( void ) { ( "コマンドを入力してください。" ); ( " 行きがけ順探索: %s ( %s ) \n " , CMD_STR[ CMD_PRE_ORDER][ CMD_STR_SHORT], CMD_STR[ CMD_PRE_ORDER][ CMD_STR_LONG] ); ( " 通りがけ順探索: %s ( %s ) \n " , CMD_STR[ CMD_IN_ORDER][ CMD_STR_SHORT], CMD_STR[ CMD_IN_ORDER][ CMD_STR_LONG] ); ( " 帰りがけ順探索: %s ( %s ) \n " , CMD_STR[ CMD_POST_ORDER][ CMD_STR_SHORT], CMD_STR[ CMD_POST_ORDER][ CMD_STR_LONG] ); ( " 終了する: %s ( %s ) \n " , CMD_STR[ CMD_EXIT][ CMD_STR_SHORT], CMD_STR[ CMD_EXIT][ CMD_STR_LONG] ); ( "" ); } /* 空白行を出力 */ void print_blank_lines( void ) { ( "" ); ( "" ); } /* コマンドを受け付ける */ enum CmdRetValue_tag get_cmd( void ) { char buf[ 20 ]; ( buf, sizeof ( buf) ); enum Cmd_tag cmd = CMD_NUM; for ( int i = 0 ; i < CMD_NUM; ++ i ){ if ( strcmp( buf, CMD_STR[ i][ CMD_STR_SHORT] ) == 0 || strcmp( buf, CMD_STR[ i][ CMD_STR_LONG] ) == 0 ){ = i; break ; } } if ( 0 <= cmd && cmd < CMD_NUM ){ return CMD_FUNC[ cmd](); } else { ( "そのコマンドは存在しません。" ); } return CMD_RET_VALUE_CONTINUE; } /* preコマンドの実行 */ enum CmdRetValue_tag cmd_pre_order( void ) { ( "行きがけ順探索で、節の値を書き出します。" ); ( gTree ); return CMD_RET_VALUE_CONTINUE; } /* inコマンドの実行 */ enum CmdRetValue_tag cmd_in_order( void ) { ( "通りがけ順探索で、節の値を書き出します。" ); ( gTree ); return CMD_RET_VALUE_CONTINUE; } /* postコマンドの実行 */ enum CmdRetValue_tag cmd_post_order( void ) { ( "帰りがけ順探索で、節の値を書き出します。" ); ( gTree ); return CMD_RET_VALUE_CONTINUE; } /* exitコマンドの実行 */ enum CmdRetValue_tag cmd_exit( void ) { ( "終了します。" ); return CMD_RET_VALUE_EXIT; } /* 行きがけ順探索でトラバース */ void pre_order( BinaryTree tree) { if ( tree == NULL ){ return ; } ( " %d\n " , tree-> value ); ( tree-> left ); ( tree-> right ); } /* 通りがけ順探索でトラバース */ void in_order( BinaryTree tree) { if ( tree == NULL ){ return ; } ( tree-> left ); ( " %d\n " , tree-> value ); ( tree-> right ); } /* 帰りがけ順探索でトラバース */ void post_order( BinaryTree tree) { if ( tree == NULL ){ return ; } ( tree-> left ); ( tree-> right ); ( " %d\n " , tree-> value ); } /* 標準入力から1行分受け取る 受け取った文字列の末尾には '\0' が付加される。 そのため、実際に受け取れる最大文字数は size - 1 文字。 引数: buf: 受け取りバッファ size: buf の要素数 戻り値: buf が返される */ void get_line( char * buf, size_t size) { ( buf, size, stdin); // 末尾に改行文字があれば削除する char * p = strchr( buf, ' \n ' ); if ( p != NULL) { * p = ' \0 ' ; } } 二分木に持たせるデータは、create_binary_tree関数の中で固定的に作っています。図にすると、次のような形になっています。
二分木
なんだか適当につくっていると思われたかもしれません。木構造へ適切に要素を追加していくには、それなりの手順が必要です。この話は、次の章 で取り上げることにして、ここではこれでよしとしておきます。
この二分木に対して、行きがけ順探索をおこなうと、
行きがけ順探索で、節の値を書き出します。
0
1
2
3
4
5
6通りがけ順探索をおこなうと、
通りがけ順探索で、節の値を書き出します。
2
1
4
3
5
0
6帰りがけ順探索をおこなうと、
帰りがけ順探索で、節の値を書き出します。
2
4
5
3
1
6
0というように出力されます。
それぞれの走査は、行きがけ順探索は pre_order関数、通りがけ順探索は in_order関数、帰りがけ順探索は post_order関数の中で行っています。幅優先探索については、練習問題 に残しておくことにします。
これらの実装を見ると分かるように、すべて再帰処理📘 C言語編第53章参照 )が行われています。
「再帰的な性質 」のところで説明したように、木構造は再帰的な構造をしており、再帰処理を活用すれば、短いコードで大きな仕事を行えます。これらの走査関数がいずれも、非常に短いコードで実装されていることが分かると思います。
最後に、delete_binary_tree関数も確認しておきましょう。create_binary_tree関数の中で二分木を作るとき、各節を malloc関数 で確保したメモリに作っているので、削除するときには free関数 を呼ぶ必要があります。問題はそれを呼ぶ順番です。
子よりも先に親を解放📘 。帰りがけ順探索ならば、「左の子→右の子→親」の順番でアクセスできるからです。
これらの走査方法のどれかがはっきりと優れているということはありませんが、効率良く目的の処理をおこなうためにはどれが適切なのかを判断できる必要はあるので、どういう順序で節を参照することになるのか理解しておきましょう。