ビットフィールド 🔗
構造体や共用体のメンバが使用するメモリの大きさを、ビット単位で指定できます。このような指定が行われたメンバを、ビットフィールド (bit-field) と呼びます。
普通に型を指定するだけでは、もっとも小さい char型を使っても、1バイトを下回ることはできませんが、ビットフィールドを使えば、最小で 1ビットにまで切り詰めることが可能です。
ただし、ビットフィールドは、処理系📘に依存する部分が非常に多い機能です。移植性📘を高くすることが難しいので、複数の処理系に対応させたいときは十分に検証するようにしてください。
ビットフィールドを使うには、構造体や共用体の定義の際に、メンバに割り当てるビット数を併記するように記述します。
struct タグ名 {
型 メンバ名 : ビット数;
型 メンバ名 : ビット数;
型 メンバ名;
:
};
union タグ名 {
型 メンバ名 : ビット数;
型 メンバ名 : ビット数;
型 メンバ名;
:
};「ビット数」の指定があるメンバと、指定のないメンバは混在しても構いません。
「ビット数」には、結果が 0 以上になる整数の定数式📘を指定します。これが、そのメンバの大きさになります。0 の場合は特別な意味を持つので、これは後であらためて説明します。また、メンバの型の本来の大きさを超えることはできません。
ビット数の指定をおこなう場合、そのメンバの型は、int型、signed int型、unsigned int型、_Bool型、あるいは処理系定義📘の型のいずれかでなければなりません。大きさはビット数の指定で決めるので、型の本来の大きさは無関係です。
int型と signed int型は、この場面に限っては異なる意味を持ちます。signed int型を指定した場合は、必ず符号付き整数ですが、単に int型とした場合の符号の有無は処理系定義📘です。そのため、ビットフィールドでは、単なる int型は避けた方が無難です。
ビットフィールドの大きさはビット単位ですが、構造体や共用体全体の大きさは、いつもバイト単位です。これは、構造体や共用体のオブジェクト📘のメモリアドレス📘を表現できなければならないためです(そうでないと、その構造体や共用体を指すポインタを表現できません)。
実際にどれだけの大きさになるかは処理系が決定することになっており、具体的な大きさは分かりません。なお、この大きさを記憶域単位 (addressable storage unit) と呼びます。
試しに、1バイトを下回るビットフィールドだけを持った構造体を定義して、その大きさを出力してみましょう。
#include <stdio.h>
struct Data {
signed int a : 5;
};
int main(void)
{
printf("%zu\n", sizeof(struct Data));
}実行結果:
4Data構造体には、5ビットを割り当てたメンバしかないですが、Visual Studio 2017 や gcc 6.4.0 (MinGW-w64) で確認すると、4 という出力が得られます。つまり、記憶域単位は 4バイトのようです。
もし、構造体全体が1つの記憶域単位で収まらないほど大きいのなら、記憶域単位の倍数の大きさが取られます。
あるビットフィールド(a) が、記憶域単位を使いきらなかった場合、次のビットフィールド(b) がその残りの部分を使おうとします。
このとき、b が必要としているビット数が、a が余らせたビットに納まりきらないときは、入る分だけを入れて、入りきらなかった分を次の記憶域単位へ入れるか(つまり、2つの記憶域単位をまたがるか)、諦めて b の全体を次の記憶域単位へ入れるかは処理系定義📘です。
このようなルールを把握したうえで、ビットフィールドを並べる順番を工夫しましょう。工夫せずに使うと、トータルのメモリ使用量が減らないかもしれません。たとえば、次のサンプルプログラムを見てください(これは、Visual Studio 2017、gcc 6.4.0 (MinGW-w64) で確認しています)。
#include <stdio.h>
struct Data {
signed int a : 15;
signed int b : 20;
signed int c : 15;
signed int d : 10;
};
int main(void)
{
printf("%zu\n", sizeof(struct Data));
}実行結果:
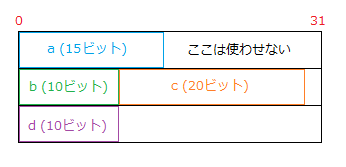
124つのビットフィールドの合計ビット数は、60ビットです。そのため、8バイト (64ビット) あれば足りるはずですが、構造体全体の大きさは 12バイト (96ビット) になっています。
このような結果になるのは、この環境では、記憶域単位が 32ビットであり、前のビットフィールドが余らせた領域が不足なら使わず、次の記憶域単位を割り当てるからです。
a (15ビット) が余らせた 17ビットでは、b を収めることができないため、a と b が異なる記憶域単位を使います。さらに、b (20ビット) が余らせる 12ビットには c が収まらないため、c もまた新たな記憶域単位を使ってしまいます。c (15ビット) が余らせる 17ビットに d は収められるので、c と d は同じ記憶域単位を使います。
つまり、以下のような状態です。
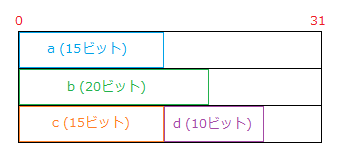
ここでは、各ビットフィールドが、1つの記憶域単位内でメモリアドレスの下位から上位へ向かって配置されるようにイメージしています。この点に関しても処理系定義📘となっており、上位から下位へ向かって配置されることもあります。
ビットフィールドの並び順を組み替えてみます。
#include <stdio.h>
struct Data {
signed int a : 15;
signed int c : 15;
signed int b : 20;
signed int d : 10;
};
int main(void)
{
printf("%zu\n", sizeof(struct Data));
}実行結果:
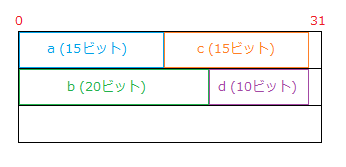
8今度は 8バイトになりました。
a が余らせた 17ビットの中に c (15ビット) を収められるので、a と c が1つの記憶域単位を共有できます。また、b は新たな記憶域単位を使いますが、12ビット余るので、d (10ビット) を収められます。
つまり、以下のような状態です。
繰り返しになりますが、この結果は、記憶域単位が 32ビットであり、前のビットフィールドが余らせた領域が不足なら使わず、次の記憶域単位を割り当てる環境での話です。ルールが異なる環境では結果はまるで違ったものになります。