トップページ – C言語編
共用体 🔗 共用体 📘
共用体自身も型であり、共用体型 (union type) と呼ばれます。構造体型や列挙型📘
共用体型の定義は次のように行います。
union タグ名 { ; ; : }; 共用体を表すキーワードは union 📘
「タグ名」には、タグ(共用体タグ) (tag、union tag) に付ける名前を記述します。構造体のタグと同じで、複数の共用型を区別するために使う名前です。共用体型の名前を使うときには「union タグ名」のように記述します。
「タグ名」は省略することが可能です。 ただし省略してしまうと、それ以降「union タグ名」の形の記述ができなくなってしまうため、使い方が限定されます。
「型 メンバ名;」の部分についても構造体型のときと同じです。初期化子📘 共用体のメンバの名前は、その共用体型に所属するものであって、他の場所にある名前と被っても問題ありません 。
定義の仕方は構造体とよく似ていますが、共用体では、それぞれのメンバが、同じメモリアドレス📘
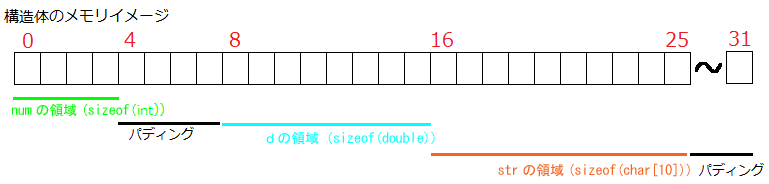
struct S_tag { int num; double d; char str[ 10 ]; } s; union U_tag { int num; double d; char str[ 10 ]; } u; このように同じメンバで構成される構造体型と共用体型を定義したとして、それぞれの変数を定義したとします。すると、メモリ上のイメージは次のようになります(sizeof(int) == 4、sizeof(double) == 8、8バイト単位でのアラインメント📘
構造体の方は知ってのとおり、各メンバが順番にメモリ上に配置されていきます。したがって、各メンバが使うメモリ領域は分かれています。メンバのメモリアドレスを調べれば、当然すべて異なります。
一方、共用体の方は、各メンバが使うメモリ領域の先頭がそろっており、同じメモリ領域を部分的に共有しています。そんなことが可能であるはずがないと思うかもしれませんが、もちろん条件はあって、共用体のメンバは同時には使えません。ある1つの共用体について、ある瞬間に値を持っているのは、どれか1つのメンバだけなのです 。ですから、使いどころはそれなりに限られてきます。
なお、構造体の場合はメンバ間や最後のメンバの終わりに、共用体の場合は一番大きいメンバが使う領域の後ろに、パディング📘 第26章 )が加わることがあります 。先ほどのイメージ図にもパディングを入れてあります(ここでは 8の倍数のバイト数に調整されることを想定しています。実際には、これとは異なる入り方をするかもしれません)。
このイメージ図のとおり、構造体型の大きさは、すべてのメンバの大きさを足し合わせたもの+パディングですし、共用体型の大きさは、一番大きいメンバの大きさ+パディングです 。
#include <stdio.h> struct S_tag { int num; double d; char str[ 10 ]; }; union U_tag { int num; double d; char str[ 10 ]; }; int main( void ) { ( "struct: %zu\n " , sizeof ( struct S_tag)); ( "union: %zu\n " , sizeof ( union U_tag)); } 実行結果:
struct: 32
union: 16また、共用体の各メンバのメモリアドレスは同一ですし、共用体型の変数自体のメモリアドレスを取っても、やはり同じです 。
#include <stdio.h> union U_tag { int num; double d; char str[ 10 ]; }; int main( void ) { union U_tag u; ( " %p\n " , & u); ( " %p\n " , & u. num); ( " %p\n " , & u. d); ( " %p\n " , u. str); } 実行結果:
006FFE84
006FFE84
006FFE84
006FFE84
共用体変数の初期化 🔗 共用体型は、型を定義するときのコードの見た目に反して、実際的にはある瞬間に有効な要素は1つしかありません。ですから、構造体型や配列型のような集成体型📘
明示的に初期値を与えなかった場合、自動記憶域期間📘 📘 (第22章 )。暗黙的に初期化される場合は、先頭に宣言したメンバに対して行われます。
共用体変数の宣言と同時に初期値を与えるには、次のように書きます。
同時に使えるメンバは1つなので、初期化子はつねに1つだけです。
【C23】空の {} による初期化が可能になりました。この場合、最初のメンバの型に応じたデフォルトの値で初期化されます。またパディング(第26章 )については 0 のビットで埋められます。[3]
通常の方法では、先頭に宣言したメンバに対してしか初期化できませんが、要素指示子 を使うと、任意のメンバに対して初期化できます。
union Data_tag { int num; char c[ 4 ]; }; int main( void ) { union Data_tag data = { 123 }; } また、自動記憶域期間を持つ場合は、同じ型の別の共用体変数を使って初期化できます。この場合、元の共用体変数と同じ値を持った状態に初期化されます。
void f( void ) { union Data_tag data1 = { 123 }; union Data_tag data2 = data1; static union Data_tag data2 = data1; // コンパイルエラー(自動記憶域期間を持たないため }
要素指示子 🔗 要素指示子を使うと、特定のメンバを選んで初期値を与えられます。
#include <stdio.h> union Data_tag { int num; char c[ 4 ]; }; int main( void ) { union Data_tag data = {. c = "abcd" }; ( " %c%c%c%c\n " , data. c[ 0 ], data. c[ 1 ], data. c[ 2 ], data. c[ 3 ]); } 実行結果:
abcd共用体変数 data の初期化のところを見てください。「.c = “abcd”」という記述によって、c というメンバに初期値 “abcd” が与えられます。このように、「.メンバ名 = 初期値」という構文が使えます。
基本的な使い方 🔗 では、実際に使ってみます。
#include <stdio.h> #include <string.h> union Data_tag { int num; char c[ 4 ]; }; int main( void ) { union Data_tag data = { 123 }; ( " %d\n " , data. num); ( data. c, "abcd" , 4 ); ( " %c%c%c%c\n " , data. c[ 0 ], data. c[ 1 ], data. c[ 2 ], data. c[ 3 ]); } 実行結果:
123
abcd共用体のメンバの参照は、構造体と同じように .演算子で行います。ポインタ経由の場合には、->演算子が使える点も同様です 。
このサンプルプログラムでは、共用体Data_tag は 4バイトの大きさを持つというつもりで定義しました。その 4バイトのメモリ領域を、int型 (num) としても扱えるし、要素数4 の char型配列 (c) としても扱えるようになっています。
このような共用体の使い方をすると、整数と文字列が混在するようなデータ表を少ないメモリで実現できます。構造体で実現すると、一方のメンバを使った場合には他方のメンバはまったく未使用なままになってしまい、無駄なメモリを使ってしまいます。
共用体の使い方として注意しなければならないのは、最後に値を入れたメンバからしか、値を正しく取得できる保証がない という点です。
たとえば、data.num に代入した直後で data.c の値を調べると、どんな結果が返ってくるか分かりません。同じメモリ領域を共有しているのだから、以下のコードで ‘a’ が出力されるように思えますが、その保証はありません。
. num = 'a' ; ( " %c\n " , data. c[ 0 ]); しかし現実には、このような使い方をしているプログラムは多くあります。特定の処理系📘 📘
このように、最後にどのメンバへ値を入れたのかを意識してプログラムを書く必要があります。現在どのメンバの値が有効になっているかを知る手段があればよいのですが、そのような方法は用意されていません。そのため、使い方がやや複雑になる場合には、最後にどのメンバへ値を入れたのかを、自前で管理すると良いかもしれません。
次のサンプルプログラムのように、共用体を構造体のメンバにして、構造体の側に管理用の変数を置く方法があります。
#include <stdio.h> #include <string.h> #include <assert.h> enum ValueType_tag { , // int型 , // char型配列 }; struct Data_tag { enum ValueType_tag value_type; // 最後に値を格納したときの型 union Value_tag { int num; char c[ 4 ]; } v; }; void set_int_value( struct Data_tag* data, int value); void set_string_value( struct Data_tag* data, const char * value); void print_value( const struct Data_tag* data); int main( void ) { struct Data_tag data; (& data, 123 ); (& data); (& data, "abcd" ); (& data); } /* int型として値を格納する 引数: data: 構造体のメモリアドレス value: 格納する値 */ void set_int_value( struct Data_tag* data, int value) { -> v. num = value; -> value_type = VALUE_TYPE_INT; } /* 文字列として値を格納する 引数: data: 構造体のメモリアドレス value: 格納する値。末尾の '\0' を含めず4文字でなければならない。 */ void set_string_value( struct Data_tag* data, const char * value) { ( strlen( value) == 4 ); ( data-> v. c, value, 4 ); -> value_type = VALUE_TYPE_STRING; } /* 現在の型に応じて正しい値を出力する 引数: data: 構造体のメモリアドレス */ void print_value( const struct Data_tag* data) { switch ( data-> value_type) { case VALUE_TYPE_INT: ( " %d\n " , data-> v. num); break ; case VALUE_TYPE_STRING: ( " %c%c%c%c\n " , data-> v. c[ 0 ], data-> v. c[ 1 ], data-> v. c[ 2 ], data-> v. c[ 3 ]); break ; default : (! "型が不適切です。" ); break ; } } 実行結果:
123
abcd構造体のメンバとして、共用体定義とその変数宣言を含めています。また、構造体のメンバには、列挙型変数が含まれています。
メモリ領域が共有されているのは、共用体の中にある num と c であって、列挙型変数の value_type は無関係であることに注意してください。つまり、num と c のどちらが有効なタイミングであっても、value_type を参照することは、つねに問題のない行為です。
共用体変数への代入と、値の出力を関数化することで、つねに列挙型変数value_type を使って適切なメンバが参照されるようになっています。もちろん、つねにこれらの関数を経由するようにプログラムを書かないといけませんが、それを守っていれば正常な状態が保たれるはずです。
列挙型の変数が加わったことによって、構造体全体の大きさが増えてしまうので、これではメモリの節約効果がありませんが、共用体部分の大きさがもっと大きければ意味があります。
構造体を含む共用体 🔗 メモリ領域を共有したいメンバが1組だけならば、これまでみてきたように共用体型の定義内にメンバを書き並べればいいですが、共有したいメンバが複数組ある場合はどうすればいいでしょうか。たとえば、“int型の a と b” あるいは “double型の a と b” のいずれかの組でメモリを使いたいという場合です。
このような場合には、組み合わせの部分を構造体にします。
union U_tag { struct { int a; int b; } v1; struct { double a; double b; } v2; }; 共用体の型定義の中に書き並べるものは、あくまでメンバ(変数)の宣言であって、型の定義ではないので、構造体の型定義と同時に、v1 と v2 という名前でメンバの宣言も行っていることに注意してください。
a や b といったメンバを参照するには、u.v1.a だとか u.v2.b といったように、v1 や v2 を経由する必要があります。
【C11】匿名構造体が可能になったため、不要なら v1 と v2 の名前を省けるようになっています[1] 構造体 」のページを参照)。また、匿名共用体 (anonymous union) も可能になっており[2]
共用体型の変数を明示的に初期化する場合で、要素指示子を使わない場合は先頭のメンバに初期値を与えなければならないので(「共用体変数の初期化 」の項を参照)、v1 の方に合わせて行います。
#include <stdio.h> union U_tag { struct { int a; int b; } v1; struct { double a; double b; } v2; }; int main( void ) { union U_tag u = {{ 10 , 20 }}; ( " %d %d\n " , u. v1. a, u. v1. b); . v2. a = 3.5 ; . v2. b = 5.5 ; ( " %lf %lf\n " , u. v2. a, u. v2. b); } 実行結果:
10 20
3.500000 5.500000要素指示子を使えば、v2 のほうを対象にして初期化できます(「要素指示子 」の項を参照)。
#include <stdio.h> union U_tag { struct { int a; int b; } v1; struct { double a; double b; } v2; }; int main( void ) { union U_tag u = {. v2 = { 3.5 , 5.5 }}; ( " %lf %lf\n " , u. v2. a, u. v2. b); } 実行結果:
3.500000 5.500000単にメンバの組み合わせを表現するためだけに構造体を定義しているので、構造体のタグ名を省略していますが、必要であれば書いても構いません。その場合は、構造体の型定義自体は外に出した方が分かりやすいかもしれません。
struct IntValues_t { int a; int b; }; struct DoubleValues_t { double a; double b; }; union U_tag { struct IntValues_t v1; struct DoubleValues_t v2; };
練習問題 🔗 問題① 「幅」と「高さ」のペアを、int型、あるいは float型で管理できるような共用体を作成してください。
解答ページはこちら 。
更新履歴 🔗
2024/11/30
2024/11/17
2023/3/5
コーディング規約を統一(要素を書き並べるとき { の直後と、} の直前に空白を入れない)
2023/2/15
コーディング規約を統一(変数や関数の名前をスネークケースにする)
2023/2/12
初出の重要用語に英語表記を併記
double型の値を printf関数で出力するとき、%lf を使うように修正
≪さらに古い更新履歴≫
2023/2/5
コーディング規約を統一(for、if などの () の前後の空白の空け方)
2023/2/4
コーディング規約を統一(実引数がある関数呼び出しの ( の直後、) の直前に空白を入れない)
2021/12/11
main関数から return 0; を削除(C言語編全体でのコードの統一)
2019/8/6
「コンパイラ」よりも「処理系」の方が適切ならば、「処理系」と書くように統一
2019/7/18
解説のベースを C99 に上げる対応
「C99 (要素指示子)」の項を「要素指示子 」に変更
コメントを // 形式で統一
2019/7/9
解説のベースを C99 に上げる対応
size_t型の出力に “%zu” を使うように修正
2018/5/21
全体的に内容を強化。
2018/5/19
ビットフィールドの話題を、第56章 へ移動。
2018/5/7
新規作成第50章 に含まれていた内容を移動してきて、手直し。
前の章へ (第54章 乱数)
次の章へ (第56章 ビットフィールド)
C言語編のトップページへ
Programming Place Plus のトップページへ
先頭へ戻る