トップページ – C言語編
構造体へのポインタ 🔗
ここまでの章にも少しだけ登場していますが、構造体変数を指し示すポインタを作れます。
#include <stdio.h>
typedef struct {
int x;
int y;
} Point;
int main(void)
{
Point point;
Point* p = &point;
point.x = 10;
point.y = 20;
printf("%d %d\n", (*p).x, (*p).y);
}
実行結果:
10 20
構造体のメンバをアクセスするとき、通常はドット演算子を使います。それに忠実にならうなら、このサンプルプログラムのように、「(*p).x」といった少々面倒な記述が必要です。つまり、まず間接参照📘を行って、構造体変数を参照し、そこからさらにドット演算子を使って任意のメンバを参照します。
これはこれで正しいのですが、ポインタ経由で構造体のメンバにアクセスする機会は結構多いので、こういう記述をするのは面倒です。そこで、-> で表現されるアロー演算子(矢印演算子) (arrow operator) を使うのが一般的です。-> は - と > の2文字を合体させたものです。アロー演算子は、(*p).x のような記述に対する構文糖であると言えます。
先ほどのサンプルプログラムを、アロー演算子を使って書き換えると、次のようになります。
#include <stdio.h>
typedef struct {
int x;
int y;
} Point;
int main(void)
{
Point point;
Point* p = &point;
point.x = 10;
point.y = 20;
printf("%d %d\n", p->x, p->y);
}
実行結果:
10 20
自己参照構造体 🔗
ある構造体のメンバに、自分自身と同じ型の構造体を含めたいことがあります。
struct Student_tag {
char* name;
int grade;
int class;
int score;
struct Student_tag next; // コンパイルエラー
};
しかし、これはコンパイルできません。構造体定義が完了するまで(} のところに到達するまで)は、この構造体は型として完全でないからです。
構造体のメンバに自分自身の型を使いたい場合には、ポインタを利用します。
struct Student_tag {
char* name;
int grade;
int class;
int score;
struct Student_tag* next; // OK
};
もちろんこれだと、メンバnext は構造体変数そのものではなく、構造体変数を指し示すポインタ変数になるので、実際に使う際には、自分でメモリアドレス📘を代入するなり、malloc関数などで確保を行い、得られたポインタを代入するなりしなければなりません。
ちなみに、自分自身のメモリアドレスを保持させることも可能です。このような構造体は、自己参照構造体 (self referencing struct) と呼ばれることがあります。
#include <stdio.h>
struct Student_tag {
char* name;
int grade;
int class;
int score;
struct Student_tag* next;
};
int main(void)
{
struct Student_tag student = {"Saitou Takashi", 2, 3, 80, NULL};
student.next = &student; // 自身を指すポインタを代入
printf("%s\n", student.next->name);
}
実行結果:
Saitou Takashi
構造体変数の定義が終わらないと、メモリアドレスが決定されないので、構造体変数を宣言する時点で、いきなり自分自身のメモリアドレスを使うことはできません。そのため、初期値としてとりあえず、NULL を与えています。
自己参照構造体は、連結リスト (linked list) というデータ構造を形作る際に必須の手法です。C言語そのものの学習から外れてしまうので、これ以上深入りしませんが、プログラムを続けていると必ず登場する必須の知識ではありますから、調べてみると良いと思います(連結リストについては、アルゴリズムとデータ構造編【データ構造】第3章で解説しています)。
offsetof 🔗
同じ構造体に含まれているメンバを指すポインタ同士を、関係演算子📘で比較した場合、手前側(構造体定義内で先に宣言されているメンバ)にある方が小さいことになります。
実際、各メンバのメモリアドレスを出力すると、メンバの宣言順に昇順📘に並びます。
#include <stdio.h>
struct Data_tag {
int a;
double b;
char c[16];
};
int main(void)
{
struct Data_tag data = {10, 1.5, "abcde"};
printf("%p\n", &data.a);
printf("%p\n", &data.b);
printf("%p\n", data.c);
}
実行結果:
006FF970
006FF978
006FF980
メンバ間に入るパディング📘の影響で、手前のメンバが使うメモリ領域の直後に、次のメンバが来ないことはあります。この実行結果でいうと、a と b の間に、4バイトのパディングがあるようです(a は 4バイト)。
offsetofマクロを使うと、構造体のメンバが、先頭からどれだけの距離のところにあるかが分かります。offsetofマクロは、<stddef.h> で以下のように定義されています。
#define offsetof(s, m) // 実装依存
s には構造体型の名前を、m にはメンバの名前を指定します。すると、s の先頭から m までのバイト数(オフセット)を表す定数式📘に置換されます。この結果は size_t型です。
offsetofマクロは、ビットフィールド(第56章)になっているメンバに対しては未定義の動作📘になります。
先ほどと同じ構造体型を使って確認してみます。
#include <stddef.h>
#include <stdio.h>
struct Data_tag {
int a;
double b;
char c[16];
};
int main(void)
{
printf("%u\n", offsetof(struct Data_tag, a));
printf("%u\n", offsetof(struct Data_tag, b));
printf("%u\n", offsetof(struct Data_tag, c));
}
実行結果:
0
8
16
a の大きさは 4バイトですが、b が 8バイト目のところにあることが明確になりました。このように、パディングの入り方を問わず、正しい位置を得られます。
アラインメント 🔗
ここまでの章でも、構造体のメンバ間や末尾に、パディング(詰め物)が入ることがあるという話をしました。そもそも、パディングが入る理由は、オブジェクト📘が、メモリ上の都合の良いメモリアドレスに配置されることを強制するためです。このような強制をおこなう要求を、アラインメント(境界調整)📘 (alignment) と呼びます。
具体的には、ある倍数のメモリアドレスにオブジェクトを配置させようとします。そうすることで、メモリアクセスが効率よく行えます。アラインメントが不適切だと、メモリアクセスの効率が低下するか、そもそもアクセス不可能となりエラーを発生させる可能性があります。
【上級】ここで起こるエラーは、アラインメントエラーとかバスエラーと呼ばれます。これは、C言語のレベルの話ではなく、ハードウェア側の問題です。このようなエラーが起こらないように、コンパイラは適切なアラインメントを行います。
このような事情から来るものなので、アラインメントが必要なのは構造体だけではありません。どんな型のオブジェクトであっても、それが適切な位置に配置されている必要性があります。
要求されるアラインメントの単位は、実行環境📘によって異なりますし、型ごとにも異なり得るものです。int型や double型などの基本的な型は、多くの場合、その型の大きさの倍数のアラインメントを要求します。int型が 4バイトなら 4 の倍数、double型が 8バイトなら 8 の倍数といった具合です。
また、ポインタが保持するメモリアドレスは、そのポインタが指し示す型の大きさに合わせたアラインメントを要求します。たとえば、int型が 4バイトであれば、int* が保持するメモリアドレスは 4 の倍数であることを求めます。void* に関しては、1 の倍数であればよく、つまりは何でも構わないということになります。
配列要素の1つ1つも、要素の型に応じたアラインメントを要求します。配列の要素は隙間なく並ぶので、先頭要素が配置されたメモリアドレスが適切であれば、後続の要素も適切な位置に置かれるはずです。たとえば、4 の倍数のアラインメントを要求し、先頭要素が 1000 という位置に置かれたなら、後続の要素は 1004、1008、1012・・・に置かれるので、すべての要素が自動的にアラインメントの要求を満たせます。
構造体の末尾にパディングが入る理由はここにあります。構造体型の配列を作ったとき、各要素が適切な位置に置かれるようにするには、構造体の大きさを適切な単位まで切り上げておかないといけません。たとえば、4 の倍数のアラインメントを要求するとします。そして、構造体の大きさが 14バイト(4 の倍数でない)だったとします。
先頭要素が 1000 という位置に置かれたのなら、後続の要素は(隙間なく詰めるという配列のルールに沿って)1014、1028、1042・・・に置かれてしまい、4 の倍数という要求を満たせないことがあります。末尾にパディングを加えて、構造体の大きさを 16バイト(4 の倍数)に調節してやれば、後続の要素は 1016、1032、1048・・・に置かれるようになりますから、すべての要素がアラインメントの要求を満たせます。
アラインメントの要求を満たすための作業は、コンパイラが適切におこなうので、基本的には、任せていれば問題になりません。たとえば、コンパイラが構造体にパディングを入れるのが、これに当たります。
また、malloc関数などの動的メモリ割り当て📘をおこなう関数は、適切にアラインメントされたメモリアドレスを返してくれることが保証されています。
【C11】アラインメントとして有効な値は、2 のべき乗の正の値であると規定されました(これに 1 は含まれます)。また、その型は size_t型で表現すると記述されています。
【C11】【C23】ある型に要求されるアラインメント値を知る手段として、_Alignof演算子 (_Alignof operator) が追加されました。_Alignof(型名) のように使用すると、アラインメント値を size_t型の定数で得られます。なお、<stdalign.h> をインクルードすると、_Alignof の代わりとして alignof という名前が使えるようになります(単なるマクロによる置き換えです)。C23 ではキーワードとしての alignof が追加されており、こちらの使用が推奨されます[1]
【C11】【C23】オブジェクトに要求するアラインメントを、デフォルトよりも厳しいものに強制する _Alignas指定子 (_Alignas specifier) が追加されています。なお、<stdalign.h> をインクルードすると、_Alignas の代わりとして alignas という名前が使えるようになります(単なるマクロによる置き換えです)。C23 ではキーワードとしての alignas が追加されており、こちらの使用が推奨されます[2]。
Visual Studio 2017 は、_Alignas に対応していませんが、代わりに __declspec(align(x)) が使えます(x にアラインメント値を指定)[3]。
【C11】動的メモリ割り当てをおこなうときにアラインメントを指定できるように、aligned_alloc関数が追加されています。Visual Studio 2017 は対応していません。
パディングの調整 🔗
構造体のパディングに関していえば、プログラマーの工夫によって入り方を調整する余地があります。たとえば、次の構造体を考えます。
struct Data_tag {
char a;
int b;
char c[20];
double d;
short e;
};
要求されるアラインメントは、char型は 1 の倍数、short型は 2 の倍数、int型は 4 の倍数、double型は 8 の倍数とします。
この場合、メモリの使われ方は次の図のようになると思われます(繰り返しになりますが、アラインメントは実行環境に応じて異なるので、必ずこのとおりになるわけではありません)。白いところがパディング、他の色のところはメンバが使っている部分です。
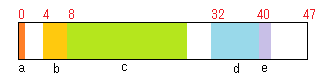 非効率なパディングの入り方
非効率なパディングの入り方
メンバ間に 2つと、末尾にパディングが入り、全体としては 48バイトになりました。たとえば、b は 4 の倍数のアラインメントを要求するので、a の後ろに 3バイトのパディングが入っています。
次に、メンバの並び順を変更して、次のように変えたとします。
struct Data_tag {
double d;
int b;
short e;
char c[20];
char a;
};
これは、要求されるアラインメントが大きい方から順に並べています。メモリは次の図のような使われ方をします。
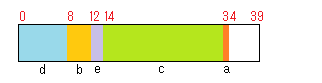 効率的なパディングの入り方
効率的なパディングの入り方
メンバ間のパディングがなくなり、末尾の 5バイト分のパディングだけになりました。結果、構造体全体の大きさも 8バイト削減されました。
このように、アラインメントの要求が大きい方から並べるようにすると、メンバ間のパディングを削減できます。ただし、後からメンバの宣言順を変えると、メンバ同士のメモリアドレスの前後関係も変わってしまうことに注意してください。
フレキシブル配列メンバ 🔗
要素数をコンパイル時📘に確定できないような可変長の配列を、構造体のメンバとして入れ込む方法があります。構造体の最後のメンバを、要素数の指定がない不完全な配列型にすることで実現できます。
struct Data_tag {
int value;
int array[]; // 要素数を空にする
};
通常、要素数の指定を空にするには、明示的な初期化が必要ですが(第25章)、構造体の末尾のメンバだけは特別にこの記法が認められます。この特殊なメンバは、フレキシブル配列メンバ (flexible array member) と呼ばれます。フレキシブル配列メンバ以外のメンバは、1個以上必要です。
この構造体型の変数を定義しても、フレキシブル配列メンバの部分には何もありません。実際、sizeof演算子を使って、構造体の大きさを確認してみると、何もないことが分かります。
#include <stdio.h>
struct Data_tag {
int value;
int array[];
};
int main(void)
{
struct Data_tag data;
printf("%zu\n", sizeof(data.value));
printf("%zu\n", sizeof(data));
}
実行結果:
4
4
メンバvalue の大きさと、構造体全体の大きさが一致しました。メンバarray の大きさがないことが分かります。なお、「sizeof(data.array)」はコンパイルエラーになります。不完全配列型の大きさはそもそも取得できないためです。
フレキシブル配列メンバの手前にパディングが入る可能性はあります。たとえば、メンバvalue を char型に変更すると、構造体全体の大きさは sizeof(char) よりも大きくなるでしょう。
フレキシブル配列メンバのメモリアドレスを取得することは可能です。
フレキシブル配列メンバによって実現したいことは、いわば、構造体が以下のような定義であるかのように扱うということです。
struct Data_tag {
int value;
int array[size];
};
つまり、要素数が定数でない配列メンバが欲しいということです。普通にこれをしようとすると、要素数の指定が定数でないという旨のコンパイルエラーになってしまいます。
この実現のためには、動的メモリ割り当てと組み合わせます。
#include <stdio.h>
#include <stdlib.h>
struct Data_tag {
int value;
int array[];
};
int main(void)
{
const size_t size = 5;
struct Data_tag* data = malloc(sizeof(struct Data_tag) + sizeof(int) * size);
data->value = 0;
for (size_t i = 0; i < size; ++i) {
data->array[i] = 10;
}
for (size_t i = 0; i < size; ++i) {
printf("%d\n", data->array[i]);
}
free(data);
}
実行結果:
10
10
10
10
10
まず、malloc関数を使ってメモリを割り当てます。このときの大きさの指定がポイントで、
sizeof(構造体全体) + sizeof(フレキシブル配列メンバの要素の型) * 要素数
とします。前述したとおり、構造体全体の大きさにはフレキシブル配列メンバの分は入っていません。そのため、フレキシブル配列メンバ以外の大きさと、配列部分として必要な大きさを合算したものを malloc関数に渡していることになります。
こうすることで、フレキシブル配列メンバ以外のメンバのメモリと、フレキシブル配列メンバのメモリの両方がまとめて確保されます。メモリが確保できれば、あとは普通の配列のように扱えます。当然、確保したメモリ領域を超えた部分へのアクセスは未定義動作📘なので厳禁です。
【上級】フレキシブル配列メンバの部分に、きちんとメモリ領域が割り当てられてさえいればアクセスできるので、必ずしも動的メモリ割り当てがセットになるとは限りませんが、大抵はそうなるでしょう。たとえば、共用体📘(第55章)を使って union U { char buf[100]; struct Data_tag data; }; のようにしても動作します。
【上級】フレキシブル配列メンバの仕様は C99規格で追加されました。それより前の時代にも、これと同じテクニックが使われることはありましたが、そのときは、構造体の末尾のメンバを要素数1の配列にすることで代用しました。この方法だと、構造体の末尾にあるのはあくまでも要素数1の配列なので、2個目以降の要素へのアクセスは未定義動作📘ということになってしまいます。それでも、多くのコンパイラは正常に動作するコードを生成したため、テクニックとして知られるようになりましたが、当然、未定義動作は避けるべきです。C99 のフレキシブル配列メンバが使えるのなら、これを使うべきです。
なお、フレキシブル配列メンバを含んだ構造体の代入では、フレキシブル配列メンバの部分は無視されます。
練習問題 🔗
問題① 「パディングの調整」の項で見た、構造体の2つの形式について、自分の環境では各メンバがどのように配置されるか、offsetofマクロを使って確認してください。
問題② 2次元上の5つの点を結んで、循環する経路を作りたいと思います。自己参照構造体を使って、このような構造を表現してください。
解答ページはこちら。
更新履歴 🔗
-
- C23 の alignof、alignas について追記
-
- コーディング規約を統一(要素を書き並べるとき
{ の直後と、} の直前に空白を入れない)
-
-
-
- コーディング規約を統一(for、if などの
() の前後の空白の空け方)
≪さらに古い更新履歴≫
-
- コーディング規約を統一(実引数がある関数呼び出しの
( の直後、) の直前に空白を入れない)
-
- main関数から
return 0; を削除(C言語編全体でのコードの統一)
-
-
-
- Visual Studio 2015 の対応終了。
-
-
- 「NULL」よりも「ヌルポインタ」が適切な箇所について、「ヌルポインタ」に修正。
-
- bsearch関数でサーチをおこなう対象の配列は、昇順でソートされていなければならないことを明記した。
-
- 全面的に文章を見直し、修正を行った。
章のサブタイトルを変更(高度な使用法 -> 関数ポインタ)
「volatile修飾子」の項を削除。
「コールバック(qsort関数、bsearch関数)」の項を、「qsort関数」と「bsearch関数」に分離。
-
- 「const修飾子」の項を削除。 すべての話題は、第32章で扱うことにした。
const に関する練習問題①を、第33章へ移動。
-
- 非ポインタに対する const修飾子の話題を、第32章で扱うようにしたので削除した。
-
-
- 「サイズ」という表記について表現を統一。 型のサイズ(バイト数)を表しているところは「大きさ」、要素数を表しているところは「要素数」。
-
- 配列の要素数を求めるマクロを、他のページと同じ形の SIZE_OF_ARRAYマクロに統一。
-
-
-
前の章へ (第36章 ポインタ⑥(データ構造の構築))
次の章へ (第38章 ポインタ⑧(関数ポインタ))
C言語編のトップページへ
Programming Place Plus のトップページへ
先頭へ戻る