トップページ – C言語編
バイナリファイル 🔗 前章 までに扱ってきたファイルは、文字だけで構成されていました。このようなファイルは、テキストファイル📘 📘 バイナリデータ 📘
0 と 1 のビットの並びを使って何を表現するのかが問題ですが、何でも表現できます。バイナリファイルは、文字、画像や音声、動画といったさまざまな形式のデータを扱うことが可能です。文字ならば、ある文字をどういうビットの並びで表現するのか、画像ならば、ある色の点をどういうビットの並びで表現するのか。そういったルール付けさえすれば、どんなデータでも表現できるわけです。
バイナリファイルは文字も扱えるので、バイナリファイルをテキストファイルのように扱うこともできなくはないです。何かが違うのかというと、改行の扱いが違います。
テキストファイルとして読み書きをおこなう場合、改行文字を本当に “改行” の意味で扱いますが、バイナリファイルの場合は単なるビットの並びでしかありません。 そもそも、文字だけを扱う形式ではないので、「行を変える」という感覚自体がありません。改行文字に関する話は、後であらためて取り上げることにします 。
なお、環境によっては、テキストファイルとバイナリファイルを区別しないこともあります。
バイナリデータを確認する 🔗 まずは、イメージを掴むために、実際にバイナリファイルの中身を見てみることにしましょう。テキストファイルをテキストエディタで確認できるように、バイナリファイルは、バイナリエディタ 📘
「エディタ」は編集者ということなので、書き換えを行いそうな感じですが、バイナリエディタの場合は、あまり書き換えることは多くないです。テキストと違って、簡単には読み解けないことが多いので、自由に思いどおりに書き換えるのはなかなか難しいです。
バイナリエディタは、無料で簡単に入手できるので、ダウンロード&インストールをしておきましょう。何を使っても構いませんが、ここでは DANDP Binary Editor(作者様のサポートページ )を使ってみます。ダウンロードから、インストールまでの流れについては割愛します。macOS ならば、HexEdit(公式プロジェクト )などがあります。
のちほど、バイナリファイルを作るサンプルプログラム を作りますが、そこで作る予定の test.bin というファイルをバイナリエディタで読み込ませてみます。
ファイルの拡張子 “.bin” は、バイナリ(Binary) を表す一般的な拡張子で、よく使われます。どんな意味合いのデータなのかはよく分からない不明瞭な拡張子です。
バイナリエディタでは次のように表示されます。
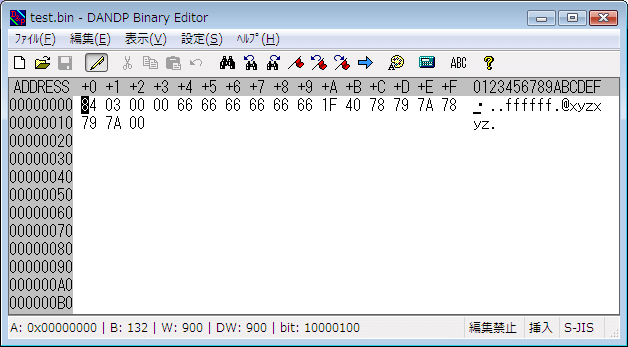
DANDP Binary Editor での表示
test.bin は、「900」という int型の整数値、「7.85」という double型の浮動小数点数、「“xyzxyz”」という文字列を書き込んだバイナリファイルです。
左端の列に、アドレスが表示されています。このアドレスはメモリアドレス📘 第40章 )にあたるものです。
その右側には、バイナリデータを 16進数で表記した羅列が表示されています。test.bin には「900」「7.85」「“xyzxyz”」が書き込まれているはずですが、バイナリエディタで見るとこのように、元が何であったか分からないような表示になります。
意味があるファイルならば、そのデータフォーマットには規則があるので、知識があれば読み解けます。
右端には、各バイト📘 ASCIIコード (ASCII code) と呼ばれる文字の表現形式が使われているのですが、この話題は後述します 。
ともかく、各バイトを文字化しているだけなので、元々「900」だったものが「9」「0」「0」のように表示されるわけではありません。「900」という整数値を 1バイトごとに切り分けても、「9」「0」「0」にはならないのです。では、どうなるのか。
「900」はファイルの先頭に書き込まれているので、アドレス 00000000~00000003 の 4バイト分を見てみましょう(int型が 4バイトの環境で作ったファイルなので 4バイト分をみます)。16進法で、84030000 となっていることが分かります。
まず、900 という 10進数が、16進数でいくつになるか調べてみます(手作業での変換については、「情報処理技術編 >基数 」で解説しています)。すると、0x384 であることが分かります。これがどうして、84030000 という表示になってしまうのかは、しっかり理解しておく必要があります。
この理解のためには、エンディアン (endian) という考え方を知る必要があります。
エンディアン 🔗 エンディアン(あるいはバイトオーダー (byte order))は、2バイト以上あるデータをメモリ上に配置するとき、各バイトをどのように並べるのかというルールのことです。現在、圧倒的多数を占めている方式は、リトルエンディアン (little endian) とビッグエンディアン (big endian) という2つの方式です。
まず、0x384 という数値は実際には 4バイトの整数として書き出したものなので、「0x00 0x00 0x03 0x84」の4つのバイトに分けられます。
これに対して、バイナリエディタ上に表示されているのは、「0x84 0x03 0x00 0x00」なので、どうやら並びが変わっているだけのようです。このように、「0x00 0x00 0x03 0x84」という順番のデータを、逆の順番「0x84 0x03 0x00 0x00」のように並べる方式は、リトルエンディアン方式です 。もし、ビッグエンディアン方式であれば、「0x00 0x00 0x03 0x84」は、そのままの順番「0x00 0x00 0x03 0x84」で並びます 。
Windows や macOS が動くコンピュータは、Intel系の CPU を使用しており、Intel が採用している方式はリトルエンディアンです。他の環境ではビッグエンディアン方式を使っている可能性もあるので、多様な使い方をするデータ、プログラムでは、エンディアンの違いを考慮しなければなりません。
【上級】たとえば、エンディアンが異なるコンピュータ同士をネットワーク📘
一見、リトルエンディアン方式は素直でないように見えるかもしれませんが、実際には数値の下位の桁ほど、若いアドレスに配置されているのですから、そういう視点で見ると素直な並びであるともいえます。実際、そのおかげで、4バイトの整数を 2バイトに切り詰めるような処理は効率的に実現できます(上位のアドレスにあるデータを単に無視するだけで良い)。この手の処理は、ビッグエンディアン方式の方がずっと面倒です。
【C23】新たに導入された標準ヘッダ <stdbit.h> で定義されているマクロ __STDC_ENDIAN_NATIVE__ の置換結果を確認することによって、エンディアンの種類を調べられるようになりました[1]
文字コード 🔗 今度は文字列がどう表現されるのかについて説明します。
先ほどのバイナリエディタの表示で、右端のテキスト表記の部分をみると、“xyzxyz” という文字列が確認できます。アドレスにすると、0000000C~00000011 に当たりますが、この部分の 16進数の表示は「78 79 7A 78 79 7A」となっています。ここから、‘x’ という文字は 78 であり、‘y’ は 79、‘z’ は 7A だと分かります。
これは次のようなプログラムで試してみても分かります。
#include <stdio.h> int main( void ) { ( " %X\n " , 'x' ); ( " %X\n " , 'y' ); ( " %X\n " , 'z' ); } 実行結果:
78
79
7Aつまり、文字のデータであっても、内部的には、なんらかの数値として表現されていることが分かります。文字と数値との対応関係は、文字コード (character code) という考え方で取り決められています。
文字コードにはさまざまな種類があるため、異なる文字コードを使っていると、同じ ‘x’ という文字でも、数値化したときの値は異なる可能性があります。
Webサイトやメールなどで、文字化け (mojibake) が起こる原因です。
多くのバイナリエディタでは、テキスト形式で表示される部分には ASCIIコードが使われます。ASCIIコードは、7ビットで 1文字を表現する形式です 。7ビットということは、最大で 128種類の文字しか表現できない訳ですから、日本語の表示など到底不可能です。
ASCII の「A」は「American」なので、そもそも英語圏で必要がない文字のことは考えられていないのです。
実際、ASCIIコードは、半角英数字と、少しの記号類、いくつかの制御文字が含まれているだけであり、日本語の表現に関わるものは何も含まれていません。ASCIIコード表は、いたる所に掲載されているので(たとえば⇒Wikipedia )、ざっと眺めておくと良いでしょう(暗記する必要はありません)。
そのため、ファイルに書き出した文字列が “xyzxyz” のような、ASCIIコードに含まれている文字であれば、バイナリエディタ上でそのまま表示できます。しかし、ASCIIコードに含まれない文字は、バイナリエディタ上では、普通には読めない形で表示されるはずです。
C言語のプログラムでは、“日本語” のような文字列も、fputs関数などを使ってファイルへ書き出すことがあります。これは、日本語が扱える環境では、ASCIIコードとは違う、日本語の文字を含んだ文字コードを使っているからです。この話題は、第46章 で取り上げます。
ところで、バイナリエディタの表示を見ると、“xyzxyz” という文字列の直後に、テキスト表現だと ‘.’ 、16進数だと 00 という文字があります。これは、test.bin を書き出す際に、文字列の終端にある ‘\0’ も書き出したため存在するものです。つまり、‘\0’ という終端文字の正体は 00 という数値です 。テキスト表現が ‘.’ となっているのは、なんらかの表示可能な文字として表現できない文字を、‘.’ で代替するということに(このバイナリエディタが)しているからです。
fwrite関数による書き込み 🔗 それでは、バイナリファイルの読み書きをおこなうプログラムを書いてみましょう。
まずは書き込みを試します。次項 では、作成されたバイナリファイルを読み込む実験を行います。
ファイルを、バイナリファイルとして開くには、fopen関数 に指定するオープンモードに、“b” を含むものを指定します。この “b” は、バイナリ(Binary) の b です。具体的には、以下のものがあります。
オープンモード
意味
rb
バイナリファイルを読み込み用に開く
wb
バイナリファイルを書き込み用に開く
ab
バイナリファイルを追記用に開く
rb+ または r+b
バイナリファイルを読み書き両用に開く
wb+ または w+b
バイナリファイルを読み書き両用に開く
ab+ または a+b
バイナリファイルを読み書き両用で追加あるいは作成する
“r”、“w”、“a” の意味合いはこれまでの章で見てきたとおりです。つまり、以下のようになっています。
操作
rb
wb
ab
rb+ または r+b
wb+ または w+b
ab+ または a+b
読み取り
できる
できない
できない
できる
できる
できる
書き込み
できない
できる
できる
できる
できる
できる
開くとファイルの中身は…
そのまま
失われる
そのまま
そのまま
失われる
そのまま
開くとファイルポジションは…
先頭にある
先頭にある
終わりにある
先頭にある
先頭にある
終わりにある
ファイルが存在しないときに開こうとすると…
失敗する
空のファイルが作られる
空のファイルが作られる
失敗する
空のファイルが作られる
空のファイルが作られる
書き込み自体は、fwrite関数
fwrite関数は、<stdio.h> に次のように宣言されています。
size_t fwrite( const void * restrict ptr, size_t size, size_t n, FILE * restrict stream); restrict については、第57章 で取り上げます。動作に影響はないので、今は無視して問題ありません。
第1引数に、書き込みたいデータのメモリアドレスを指定します。配列の要素のメモリアドレスであっても構いません。
第2引数は、書き込むデータ1つ分の大きさを指定します。たとえば、int型の変数の値を1つだけ書き込むのであれば「sizeof(int)」のようにします。配列をまとめて書き込む場合であっても、ここには1個分の大きさを指定するので、「sizeof(array[0])」のようにします。
第3引数は、書き込むデータの個数を指定します。第1引数に指定したメモリアドレスが配列の場合に、ここに要素数を指定できます。単独のデータであれば 1 を指定します。
第4引数は、書き込み先ストリームの指定です。
戻り値は、実際に書き込まれたデータの個数が返されます。なんらかのエラーが起きたことは、第3引数の n に指定した値よりも小さい値が返されたことで判定します。
それでは実際に試してみます。
#include <stdio.h> #include <stdlib.h> int main( void ) { FILE * fp = fopen( "test.bin" , "wb" ); if ( fp == NULL) { ( "ファイルオープンに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } int num = 900 ; double d = 7.85 ; char str[] = "xyzxyz" ; if ( fwrite(& num, sizeof ( num), 1 , fp) < 1 ) { ( "ファイルへの書き込みに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } if ( fwrite(& d, sizeof ( d), 1 , fp) < 1 ) { ( "ファイルへの書き込みに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } if ( fwrite( str, sizeof ( str[ 0 ]), sizeof ( str), fp) < sizeof ( str)) { ( "ファイルへの書き込みに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } if ( fclose( fp) == EOF) { ( "ファイルクローズに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } } 実行結果(標準出力):
実行結果(test.bin):
????ffffff�@xyzxyztest.bin の中身は、テキストでは表現できない状態になっているので、実行結果上では「?」としました。バイナリエディタで開いてみると、前の項 の写真と同じ結果になっているはずです。
3度の fwrite関数の呼び出しによって、int型の値を1つ、double型の値を1つ、6文字の文字列(ヌル文字を含めて7文字)を1つ書き込んでいます。
str を書き込むとき、fwrite関数の第3引数を「sizeof(str)」としているため、ヌル文字も含まれます(第32章 )。バイナリデータなので、C言語の文字列のルールを無視して、ヌル文字を付けずに書き出しても、読み込む際に気を付ければ別に問題はありません。ヌル文字が不要なら -1 するか、strlen関数 に置き換えます。
fread関数による読み込み 🔗 次に、バイナリファイルの読み込みを行ってみましょう。先ほど の書き込みのサンプルプログラムで作成したファイルを読み込みます。
バイナリファイルの読み込みには、fread関数
fread関数は、<stdio.h> に以下のように宣言されています。
size_t fread( void * restrict ptr, size_t size, size_t n, FILE * restrict stream); restrict については、第57章 で取り上げます。動作に影響はないので、今は無視して問題ありません。
第1引数に、読み込んだデータを格納する変数のメモリアドレスを指定します。これは配列の要素のメモリアドレスであっても構いません。
第2引数は、読み込みデータ1つ分の大きさを指定します。たとえば、int型の変数の値を1つだけ読み込むのであれば「sizeof(int)」のようにします。配列をまとめて読み込む場合であっても、ここには1個分の大きさを指定するので、「sizeof(array[0])」のようにします。
第3引数は、読み込みデータの個数を指定します。第1引数に指定したメモリアドレスが配列の場合に、ここに要素数を指定できます。単独のデータであれば 1 を指定します。
第4引数は、読み込み元ストリームの指定です。
戻り値は、実際に読み込まれたデータの個数が返されます。なんらかのエラーが起きたとき、あるいは、ファイルの終わりに達していた場合には、第3引数の n に指定した値よりも小さい値が返されます。
では試してみましょう。
#include <stdio.h> #include <stdlib.h> int main( void ) { FILE * fp = fopen( "test.bin" , "rb" ); if ( fp == NULL) { ( "ファイルオープンに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } int num; if ( fread(& num, sizeof ( num), 1 , fp) < 1 ) { ( "読み込み中にエラーが発生しました。 \n " , stderr); ( EXIT_FAILURE); } double d; if ( fread(& d, sizeof ( d), 1 , fp) < 1 ) { ( "読み込み中にエラーが発生しました。 \n " , stderr); ( EXIT_FAILURE); } char str[ 7 ]; if ( fread( str, sizeof ( str[ 0 ]), sizeof ( str), fp) < sizeof ( str)) { ( "読み込み中にエラーが発生しました。 \n " , stderr); ( EXIT_FAILURE); } ( " %d\n " , num); ( " %lf\n " , d); ( " %s\n " , str); if ( fclose( fp) == EOF) { ( "ファイルクローズに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } } 実行結果(標準出力):
900
7.850000
xyzxyzfread関数で文字列を読み込む場合、ヌル文字の扱いに注意してください。fread関数は、文字列を読み込んだからといって、自動的にヌル文字を付加することはありません。 そもそも、バイナリデータを扱う関数なので、文字列なのかどうかを気にしていません。
普通、読み込んだ文字列は、そのあとの処理の中で文字列として扱うはずですから、ヌル文字が付いていないと困ります。バイナリファイル側にヌル文字も書き込まれているのなら、それごと読み込めばよいですし、書き込まれていないのなら、読み取った後で付け足すなどしなければなりません。
ところで、読み込むファイルの中身が、「int型の値、double型の値、末尾にヌル文字が付いた 7文字の文字列、が、そのような順番で並んでいる」ことを知っていないと、このプログラムを書けないことにお気づきでしょうか?
バイナリファイルの読み込みは、ファイルの内容がどんなふうになっているのか知っていないと実装できません 。1バイトずつ読み込んでみたとしても、それがどんなデータを構成している 1バイトなのかが分からないので、正しく扱うことができないのです。
また、int型と double型が登場していますが、int型の大きさが異なる環境で作成されたファイルであれば、このサンプルプログラムでは正しく読み込めないでしょう。同様に、浮動小数点数の表現方法が異なる環境で作成されていたら、やはり読み込めません。このように、バイナリファイルの読み書きは、その中身のフォーマットが正確に分かっていないと、正しく扱うことができないのです。
fread関数でのエラーチェックは、戻り値が、第3引数の値よりも小さいかどうかで判断できます。しかし、ファイルの終わりに達した場合もこの判定に引っかかってしまうので、切り分ける必要があるのなら、feof関数 を併用しなければなりません。
このサンプルプログラムでは、読み込むファイルの内容について熟知しているので、ファイルの終わりが来ることを考慮していませんが、データ件数が不明な場合などには、チェックが必要でしょう。たとえば、次のようになります。
if ( fread(& num, sizeof ( num), 1 , fp) < 1 ) { if ( feof( fp)) { // ファイルの終わり } else { // エラー発生 } }
ランダムアクセス 🔗 ランダムアクセスをおこなうためには、前の章 で説明した fseek関数を使います。テキストファイルの場合にはいろいろと制約が多かったですが、バイナリファイルの場合は自由度が高くなっています。
バイナリファイルに対する fseek関数の使用時には、第2引数の移動量のところに自由に値を指定でき、1バイト単位でファイルポジションを移動できます。
ただし、バイナリファイルに対する fseek関数において、第3引数を SEEK_END にしたときに、これがどんな結果になるかは処理系依存です 。そのため、ファイルサイズを調べるためのテクニックとして、よく使われている以下の方法は、処理系依存の方法です。
#include <stdio.h> #include <stdlib.h> long get_file_size( FILE * fp); int main( void ) { FILE * fp = fopen( "test.bin" , "rb" ); if ( fp == NULL) { ( "ファイルオープンに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } ( " %ld\n " , get_file_size( fp)); if ( fclose( fp) == EOF) { ( "ファイルクローズに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } } long get_file_size( FILE * fp) { // 現在のファイルポジションを保存 long fpos_save = ftell( fp); if ( fpos_save == - 1 L ) { ( "ファイルポジションの取得に失敗しました。 \n " , stderr); ( EXIT_FAILURE); } // ファイルの末尾まで移動して、その位置を調べる if ( fseek( fp, 0 , SEEK_END) != 0 ) { ( "ファイルポジションの移動に失敗しました。 \n " , stderr); ( EXIT_FAILURE); } long size = ftell( fp); if ( size == - 1 L ) { ( "ファイルポジションの取得に失敗しました。 \n " , stderr); ( EXIT_FAILURE); } // ファイルポジションを元に戻す if ( fseek( fp, fpos_save, SEEK_SET) != 0 ) { ( "ファイルポジションの移動に失敗しました。 \n " , stderr); ( EXIT_FAILURE); } return size; } 実行結果(標準出力):
19get_file_size関数は、fseek関数でファイルの末尾まで移動し、その位置で ftell関数 を呼び出すことによって、ファイルの先頭からの距離を調べています。バイナリファイルの場合は、ftell関数が返す値はファイルの先頭からのバイト数であることが保証されているので、この値はファイルサイズと一致します。
最後に、元のファイルポジションに戻してやるところまで面倒を見たいので、あらかじめ、ftell関数で返されるファイルポジションを保存しておき、最後にその位置に戻しています。
ファイルサイズを取得するほかの方法については、「逆引き ファイルサイズを取得する 」で取り上げています。
改行文字 🔗 バイナリファイルには、文字を含むことができるので、テキストファイルとまったく同じデータで構成されていても構いません。しかし、この章の冒頭 で触れたように、改行文字の扱いが異なります。
C言語において、改行文字といえば ‘\n’ をイメージしますが、これはC言語の文法上のルールに過ぎません。実際のファイル内に ‘\n’ がそのまま書き込まれているわけではありません。
たとえば、Windows環境で、テキストファイルに ‘\n’ を含んだ文字列を出力して、できあがったファイルをバイナリエディタで覗いてみましょう。次のプログラムで test.txt を作ります。
#include <stdio.h> #include <stdlib.h> int main( void ) { FILE * fp = fopen( "test.txt" , "w" ); if ( fp == NULL) { ( "ファイルオープンに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } // 改行文字を含んだ文字列を書き込む if ( fputs( "xyz \n xyz" , fp) == EOF) { ( "ファイルへの書き込みに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } if ( fclose( fp) == EOF) { ( "ファイルクローズに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } } 実行結果(標準出力):
実行結果(test.txt):
xyz
xyzfopen関数の第2引数は “w” なので、テキストファイルとして書き出していることに注意してください。fputs関数に、途中に改行文字を含ませた文字列を渡して、ファイルへ書き出しています。
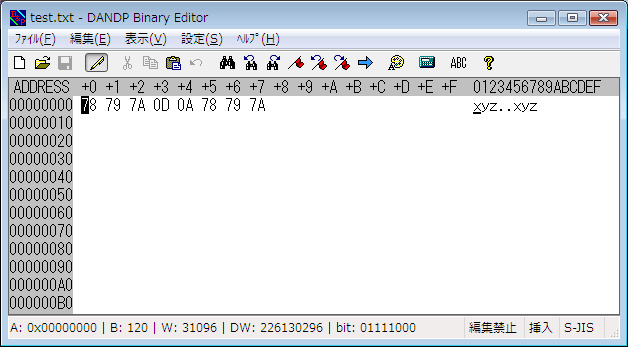
作成された test.txt を、バイナリエディタで確認すると、次のようになっています。
改行文字をバイナリエディタで確認
アドレス00000000~00000002 と 00000005~00000007 は、いずれも “xyz” ですから、その間にあるのが改行文字だと考えられます。ところが、ここには 2バイト分のデータ「0D 0A」があります。
このように、Windows環境では、改行は2バイトで表現されます 。1バイト目は、数値上「0D」で表されるキャリッジリターン(行頭復帰) 📘 ラインフィード(改行) 📘 CR 、後者を LF と略し、あわせて CR+LF のように表記することもあります。
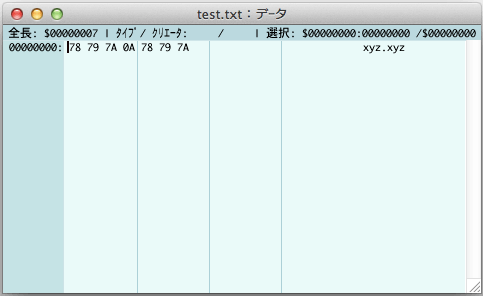
環境によっては、CR と LF のいずれか一方だけで、改行を表すこともあります。たとえば、macOS では、LF だけが使われる ので、先ほどのプログラムを macOS 環境でコンパイル・実行してみると、標準出力に現れる結果は同じに見えても、バイナリエディタで確認すると「0A」だけしかないことが分かります。
改行文字をバイナリエディタで確認
エンディアン の話と同様に、改行も環境に対する依存性があるということです。
複数ありえる改行の表現を、C言語のソースコード上では ‘\n’ という1つの表現方法に統一させることで、環境ごとの違いを吸収しています。
そして、テキストファイルとして扱う場合には、‘\n’ を出力すると、CR+LF や LF といった、その環境に応じた表現に変換します。バイナリファイルとして扱う場合には、このような変換を行わず、‘\n’ は「改行」を意味する「0A」がそのまま出力されます。
このような、改行文字の自動的な変換は、読み込みの場合にも行われます。テキストファイルとして読み込みをおこなうと、CR+LF や LF などの形で表現された改行を検出すると、‘\n’ に直して読み込みます。
先ほどのサンプルプログラムを実行して出力された test.txt を読み込んで、1文字ずつ出力するプログラムを作って確かめてみましょう。
#include <stdio.h> #include <stdlib.h> int main( void ) { FILE * fp = fopen( "test.txt" , "r" ); if ( fp == NULL) { ( "ファイルオープンに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } for ( int i = 0 ; ; ++ i) { int c = fgetc( fp); if ( feof( fp)) { break ; } else if ( ferror( fp)) { ( "読み込み中にエラーが発生しました。 \n " , stderr); ( EXIT_FAILURE); } else { // 何もしない } ( " %d : %c\n " , i, c); } if ( fclose( fp) == EOF) { ( "ファイルクローズに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } } test.txt:
xyz
xyz実行結果(標準出力):
0: x
1: y
2: z
3:
4: x
5: y
6: z出力結果の3文字目(最初を 0 とする)のところで、余分に改行されているようです。test.txt の3文字目は CR、4文字目に LF です。Windows環境では、CR+LF で改行文字を表すので、この2文字の組み合わせを ‘\n’ に変換して読み取っています。
macOS の場合は、ファイルには LF だけが書き込まれているはずです。その場合、LF を ‘\n’ に変換します。
このように、ファイルを作った環境と読み込む環境が同一ならばほとんど何も気にする必要がありません。問題になるのは、Windows で作ったファイルを macOS で読み込むような場合です。
改行が CR+LF となっているファイルを、改行が LF だと仮定しているプログラムで読み込むと、LF だけを改行と認識することになるでしょう。おそらく、改行の手前に余分なゴミ(CR) が現れます。
反対に、改行が LF となっているファイルを、改行が CR+LF だと仮定しているプログラムで読み込むと、LF 単体では改行と認識しないので、改行が行われず、いたるところにゴミ(LF) が現れます。
バイナリファイルの場合を実験してみましょう。バイナリファイルにとって、改行文字というのは、単なる 1バイトのデータ(「0A」)にすぎず、何も特別扱いはしません。
#include <stdio.h> #include <stdlib.h> int main( void ) { char str[] = "xyz \n xyz" ; FILE * fp = fopen( "test.bin" , "wb" ); if ( fp == NULL) { ( "ファイルオープンに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } if ( fwrite( str, sizeof ( str[ 0 ]), sizeof ( str), fp) < sizeof ( str)) { ( "ファイルへの書き込みに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } if ( fclose( fp) == EOF) { ( "ファイルクローズに失敗しました。 \n " , stderr); ( EXIT_FAILURE); } } 実行結果(標準出力):
実行結果(test.bin):
xyz
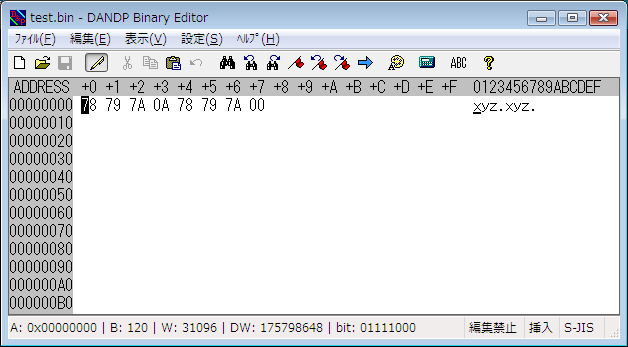
xyztest.bin をバイナリエディタで開くと、次のようになります。
改行文字をバイナリエディタで確認
今度は、改行文字の部分は「0A」という 1バイトだけになっています。「0A」は改行のことなので、特に変換せず、素直にそのまま出力されていることが分かります。この結果は、Windows でも macOS でも同じです。
ところで、C言語のソースコード上で「改行」は ‘\n’ でしたが、「復帰」の方も ‘\r’ という表現方法を持っています。テキストファイルを使う場合は、‘\r’ を使う機会はありませんが、バイナリファイルの場合には使うことがあります。
たとえば、改行が CR+LF で表現されているテキストファイルを、改行を LF だと仮定するプログラムで読み込むことを考えます。この場合は、バイナリファイルとして読み込みをおこなうようにします。すると、CR+LF の部分は、変換されることなく ‘\n’ と ‘\r’ として読み込まれます。この組み合わせを見つけたら、‘\n’ に手動で変換してやれば良いのです。
練習問題 🔗 問題① 手元にある適当なファイルをいくつかバイナリエディタに読み込ませて、中身を確認してみてください。
問題② 次のような構造体型があります。
typedef struct NameList_tag { size_t name_length; // name の文字数 (終端文字を除く) char * name; // 名前 int age; // 年齢 } NameList; この型で表現された以下のデータを、バイナリ形式でファイルへ出力するプログラムおよび、 ファイルから入力を受け取るプログラムを作成してください。
static const NameList name_list = { 4 , "John" , 29 }; 問題③ リトルエンディアンとビッグエンディアンを相互に変換するためには、どのようにすれば良いか考えてください。
問題④ 小さめで単色のビットマップ📘
問題⑤ 問題④の結果を踏まえ、赤色の単色画像を読み込んで、青色の単色画像に変換して出力するプログラムを作成してください。
問題⑥ ファイルの内容を、バイナリエディタのように整形して出力するプログラムを作成してください。
解答ページはこちら 。
参考リンク 🔗 Amazon.co.jp へのリンクはアフィリエイトリンクです。
更新履歴 🔗
2024/12/11
「エンディアン 」に、C23 でエンディアンを判定できるようになったことについてのコラムを追加
2023/2/15
コーディング規約を統一(変数や関数の名前をスネークケースにする)
2023/2/12
初出の重要用語に英語表記を併記
double型の値を printf関数で出力するとき、%lf を使うように修正
2023/2/5
コーディング規約を統一(for、if などの () の前後の空白の空け方)
2023/2/4
コーディング規約を統一(実引数がある関数呼び出しの ( の直後、) の直前に空白を入れない)
≪さらに古い更新履歴≫
2021/12/11
main関数から return 0; を削除(C言語編全体でのコードの統一)
2019/10/15
2019/8/23
練習問題⑥ が、まだ解説していない、コマンドライン引数を使ったものになっていたので、使わないかたちに変更
2019/8/20
fseek関数のエラーチェックを追加
ftell関数のエラーチェックを追加
fwrite関数のエラーチェックを追加
2019/8/19
fputs関数でファイルへ出力する際のエラーチェックを追加
2019/8/1
解説のベースを C99 に上げる対応
標準ライブラリ関数の宣言に restrict を付加
2019/7/23
解説のベースを C99 に上げる対応
ローカル変数の宣言を、ブロックの先頭以外の位置でもおこなう
2019/7/18
2019/7/15
解説のベースを C99 に上げる対応
ループ制御変数を for文の初期設定式で宣言するように修正
2018/5/25
第48章 の練習問題⑬⑭⑮を移動してきて、練習問題④⑤⑥とした。 2018/3/17
全面的に文章を見直し、修正を行った。文字コード 」として分離した。
2018/3/16
2018/2/22
「サイズ」という表記について表現を統一。 型のサイズ(バイト数)を表しているところは「大きさ」、要素数を表しているところは「要素数」。
2018/2/21
文章中の表記を統一(bit、Byte -> ビット、バイト)
2015/8/29
2014/1/31
2010/5/23
前の章へ (第41章 ランダムアクセス)
次の章へ (第43章 バッファリング)
C言語編のトップページへ
Programming Place Plus のトップページへ
先頭へ戻る